一:为何选择云计算/云计算之前遇到的问题
一、有效解决硬件单点故障问题
单点故障是指某个硬件的故障造成网站某个服务的中断。要真正解决这个问题,需要为每个硬件准备冗余,这不仅大大增加了硬件购置成本,而且部署与维护成本也不容小视。
而云计算平台是基于服务器集群,从设计之初就考虑了单点故障问题,并在建设时有效地解决了这个问题。如果一家云服务商出现单点故障问题,就如同存在银行的钱丢了。
二、按需增/减硬件资源
自己托管服务器,增/减硬件一直是头疼的问题。
1. 增加服务器的时候,购买服务器需要时间,而且这个时间自己无法控制。而使用云服务器,随时可以增加服务器——垂手可得。
2. 减服务器只能从机房拉回办公室,无法再把服务器退给厂商,购置服务器的成本就浪费了。而使用云服务器,如果下个月不用,不续费就行了(针对阿里云按月购买的情况)——想用就用,想扔就扔。
3. 不能按需增加满足基本需求的服务器配置。假如我们现在需要一台低配置的服务器用Linux跑缓存服务,如果为之单独购买一台便宜的低配置的服务器很不合算,因为这台服务器仅仅一年的电费就至少要3000元左右。所以只能尽量减少服务器数量,提高单台服务器的配置,在让一台服务器跑更多东西。而使用云服务器,需要什么样的配置就买什么样的配置,让各个服务器的职责更单一,互相之间的影响更小——职责分明,效率更高。
三、BGP线路解决南北互通问题
南北互通问题是南方电信与北方联通线路之间的互通问题,这个问题困扰我们多年,之前用过双线机房,解决的也不是很好。目前只有BGP线路才能有效解决这个问题,而拥有真正的BGP线路的机房不是很多,成本也非常高。而我准备使用的阿里云用的就是BGP线路,这也是吸引我们的主要地方之一。
究竟什么是南北互通问题?基于我们的理解简体描述一下,不对之处欢迎指出。南北互通问题实际就是路由问题。假设我们的服务器放在上海电信的机房,上海一位联通的用户访问我们的服务器,要先绕到联通的北京总出口(假设总出口在北京),然后再绕回上海。实际上这位联通用户可以通过上海的线路直接到达我们的服务器,不用绕这么远,但上海电信的机房无法告知联通的路由器走近路过来,只能按照联通路由器设定好的路由走。本来即使走北京绕一下也没有大的影响,毕竟是光的速度,但是由于大多数联通的用户访问电信网络都这么绕着走,联通的总出口成为了瓶颈,总出口流量太大时,联通的用户访问电信的网络速度就会慢。BGP线路也没什么神奇之处,只是它能决定走什么路由过来,不绕远路,问题自然解决了。它有这样的特权,就不仅能解决南北互通的问题,而且能解决其他网络的互通问题,比如教育网。因为有权限决定路由,就可以优化路由,哪条路堵,我就换条路。
四、按需增/减带宽
带宽是主要成本,托管服务器时,与ISP服务商签一年合同之前就要确定带宽。用了一段时间之后,你发现带宽买多了,想减一些是不允许的。中途要临时增加带宽一段时间也是不行的,要买就买一年(这是根据我们接触过的ISP服务商)。所以,一般都会多买一些带宽,留一些余量。
使用云服务器可以灵活地增减带宽,不会浪费带宽,即使买少了也不用担心,随时可以增加。虽然各个云服务商会有一定的限制,比如在阿里云一次至少要购买1个月的带宽,但比自己托管服务器灵活很多,同样的带宽条件,会节省不少成本,尤其是带宽需求在一年中变化比较大的网站。
五、更有吸引力的费用支付方式
在IDC机房托管服务器一般是签一年合同,一次支付一个季度的费用。
而使用云服务,一次可以支付更短时间的费用,比如阿里云可以一次只支付一个月的费用,节约了流动资金。
从总体上考虑,差不多的成本,却拥有更多的内存、更多的CPU、更多的硬盘空间、更优质的带宽线路,更重要的是可以随时按需扩展计算资源。
二:什么是云计算(资源和服务的交互方式)
一、概念分解:
云:云计算中的云,代表循环利用的意思(云多了变成雨,落到地面,云减少,水蒸发到空中,云增加)。
计算:云计算中的计算,代表计算资源,涵盖虚机、存储、网络等。
云计算:代表计算资源向云水循环一样,按需分配,循环利用。
附:企业数据中心部署在云计算分布式平台上,类似于从原来单台发电机转向电厂集中供电模式,它意味着访问计算机和存储系统也可以作为一种商品流通,就像煤气、水电一样,取用方便,费用低廉,只不过它是通过互联网传输的,云就是互联网的一种比喻
二、云计算分类:
狭义:IT基础设施的交互和使用模式,通过网络以按需,易扩展的方式获取资源
广义:服务(IT基础设施、软件等)的交互和使用模式,通过网络以按需、易扩展的方式获取资源。
三:云服务模式
一、IaaS:基础设施即服务
用户通过网络获取虚机、存储、网络,然后用户根据自己的需求操作获取的资源。 典型应用:亚马逊AWS等
二、PaaS:平台即服务
将软件研发平台作为一种服务, 如Eclipse/Java编程平台,服务商提供编程接口/运行平台等。典型应用:Google AppEngine、Force.com、微软Azure等
三、SaaS:软件即服务
将软件作为一种服务通过网络提供给用户,如web的电子邮件、HR系统、订单管理系统、客户关系系统等。用户无需购买软件,而是向提供商租用基于web的软件,来管理企业经营活动。典型应用:Google Doc、Saleforce.com、Oracle CRM On Demand、Office Live Workspace等
四:云应用形式
一.私有云
将基础设施与软硬件资源构建于防火墙内,基于iaas构建私有云平台供企业内部使用,开源组件有:openstack(最为出色),cloudstack等
二.云存储
云存储系统是一个以数据存储和管理为核心的云计算系统
三.云游戏
游戏运行云平台服务端,云平台将游戏画面解压缩后传给用户,用户端无需高配置处理器和显卡,只需要基本的视频解压缩能力即可。
四.云物联
基于云平台实现物物相连的互联网。
五.云安全
通过网状的大量客户端检测网络中软件的异常,获取木马,恶意程序的最新信息,推送到云平台服务端自动分析和处理,再把解决方案发送给每一个客户端。云平台使用者越多,越安全。
六.公有云
云平台对外开放,主要以Iaas和Paas为主,较为成熟的是Iaas,如阿里云,腾讯云,青云,ucloud,首都在线等
七.混合云
公有云和私有云的结合,即对企业内部又对企业外部,例如AWS
五:传统应用与云感知应用
一、传统应用
传统应用像养宠物,宠物病了要细心呵护
每个应用都是独特的、专门的
专门的服务器、硬件和软件保证可靠性
资源不够,增加cpu、内存、磁盘
专门的技术支持
二、云感知应用
云感知应用像养牛,牛生病了,你需要一头新的牛
应用跑在一个或多个虚拟机里
资源不够,增加新的虚拟机
应用挂起,重启或创建新的虚拟机
六:openstack与及其相关组件介绍
一、openstack由来
openstack最早由美国国家航空航天局NASA研发的Nova和Rackspace研发的swift组成。后来以apache许可证授权,旨在为公共及私有云平台建设。openstack主要用来为企业内部实现类似于Amazon EC2和S3的云基础架构服务(Iaas).每6个月更新一次,基本与ubuntu同步,命名是以A-Z作为首字母来的。
二、openstack项目与组件(服务名是项目名的别名)
核心项目3个
1.控制台
服务名:Dashboard
项目名:Horizon
功能:web方式管理云平台,建云主机,分配网络,配安全组,加云盘
2.计算
服务名:计算
项目名:Nova
nbsp; 功能:负责响应虚拟机创建请求、调度、销毁云主机
3.网络
服务名:网络
项目名:Neutron
功能:实现SDN(软件定义网络),提供一整套API,用户可以基于该API实现自己定义专属网络,不同厂商可以基于此API提供自己的产品实现
存储项目2个
1.对象存储
服务名:对象存储
项目名:Swift
功能:REST风格的接口和扁平的数据组织结构。RESTFUL HTTP API来保存和访问任意非结构化数据,ring环的方式实现数据自动复制和高度可以扩展架构,保证数据的高度容错和可靠性
2.块存储
服务名:块存储
项目名:Cinder
功能:提供持久化块存储,即为云主机提供附加云盘。
共享服务项目3个
1.认证服务
服务名:认证服务
项目名:Keystone
功能:为访问openstack各组件提供认证和授权功能,认证通过后,提供一个服务列表(存放你有权访问的服务),可以通过该列表访问各个组件。
2.镜像服务
服务名:镜像服务
项目名:Glance
功能:为云主机安装操作系统提供不同的镜像选择
3.计费服务
服务名:计费服务
项目名:Ceilometer
功能:收集云平台资源使用数据,用来计费或者性能监控
高层服务项目1个
1.编排服务
服务名:编排服务
项目名:Heat
功能:自动化部署应用,自动化管理应用的整个生命周期.主要用于Paas
三、openstack各组件详解及运行流程
各组件逻辑关系图:

OpenStack从入门到放弃
openstack新建云主机流程图:

虚拟机启动过程如下:
- 界面或命令行通过RESTful API向keystone获取认证信息。
- keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
- 界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
- nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
- keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。
- 通过认证后nova-api和数据库通讯。
- 初始化新建虚拟机的数据库记录。
- nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。
- nova-scheduler进程侦听消息队列,获取nova-api的请求。
- nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
- 对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。
- nova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。
- nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。
- nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor)
- nova-conductor从消息队队列中拿到nova-compute请求消息。
- nova-conductor根据消息查询虚拟机对应的信息。
- nova-conductor从数据库中获得虚拟机对应信息。
- nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。
- nova-compute从对应的消息队列中获取虚拟机信息消息。
- nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。
- glance-api向keystone认证token是否有效,并返回验证结果。
- token验证通过,nova-compute获得虚拟机镜像信息(URL)。
- nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。
- neutron-server向keystone认证token是否有效,并返回验证结果。
- token验证通过,nova-compute获得虚拟机网络信息。
- nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。
- cinder-api向keystone认证token是否有效,并返回验证结果。
- token验证通过,nova-compute获得虚拟机持久化存储信息。
- nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。
下面我们就围绕上图流程展开
1.keystone
User:指使用Openstack service的用户,可以是人、服务、系统,但凡使用了Openstack service的对象都可以称为User。
Project(Tenant):可以理解为一个人、或服务所拥有的 资源集合 。在一个Project(Tenant)中可以包含多个User,每一个User都会根据权限的划分来使用Project(Tenant)中的资源。比如通过Nova创建虚拟机时要指定到某个Project中,在Cinder创建卷也要指定到某个Project中。User访问Project的资源前,必须要与该Project关联,并且指定User在Project下的Role。
Role:用于划分权限。可以通过给User指定Role,使User获得Role对应的操作权限。Keystone返回给User的Token包含了Role列表,被访问的Services会判断访问它的User和User提供的Token中所包含的Role。系统默认使用管理Role admin和成员Role _member_ 。
Policy:OpenStack对User的验证除了OpenStack的身份验证以外,还需要鉴别User对某个Service是否有访问权限。Policy机制就是用来控制User对Tenant中资源(包括Services)的操作权限。对于Keystone service来说,Policy就是一个JSON文件,默认是/etc/keystone/policy.json。通过配置这个文件,Keystone Service实现了对User基于Role的权限管理。
Token:是一个字符串表示,作为访问资源的令牌。Token包含了在 指定范围和有效时间内 可以被访问的资源。EG. 在Nova中一个tenant可以是一些虚拟机,在Swift和Glance中一个tenant可以是一些镜像存储,在Network中一个tenant可以是一些网络资源。Token一般被User持有。
Credentials:用于确认用户身份的凭证
Authentication:确定用户身份的过程
Service:Openstack service,即Openstack中运行的组件服务。
Endpoint:一个可以通过网络来访问和定位某个Openstack service的地址,通常是一个URL。比如,当Nova需要访问Glance服务去获取image 时,Nova通过访问Keystone拿到Glance的endpoint,然后通过访问该endpoint去获取Glance服务。我们可以通过Endpoint的region属性去定义多个region。Endpoint 该使用对象分为三类:
- admin url –> 给admin用户使用,Post:35357
- internal url –> OpenStack内部服务使用来跟别的服务通信,Port:5000
- public url –> 其它用户可以访问的地址,Post:5000
创建完service后创建API EndPoint. 在openstack中,每一个service都有三种end points. Admin, public, internal。 Admin是用作管理用途的,如它能够修改user/tenant(project)。 public 是让客户调用的,比如可以部署在外网上让客户可以管理自己的云。internal是openstack内部调用的。三种endpoints 在网络上开放的权限一般也不同。Admin通常只能对内网开放,public通常可以对外网开放internal通常只能对安装有openstack对服务的机器开放。
V3新增
- Tenant 重命名为 Project
- 添加了 Domain 的概念
- 添加了 Group 的概念

OpenStack从入门到放弃
- 用户alice登录keystone系统(password或者token的方式),获取一个临时的token和catalog服务目录(v3版本登录时,如果没有指定scope,project或者domain,获取的临时token没有任何权限,不能查询project或者catalog)。
- alice通过临时token获取自己的所有的project列表。
- alice选定一个project,然后指定project重新登录,获取一个正式的token,同时获得服务列表的endpoint,用户选定一个endpoint,在HTTP消息头中携带token,然后发送请求(如果用户知道project name或者project id可以直接第3步登录)。
- 消息到达endpoint之后,由服务端(nova)的keystone中间件(pipeline中的filter:authtoken)向keystone发送一个验证token的请求。(token类型:uuid需要在keystone验证token,pki类型的token本身是包含用户详细信息的加密串,可以在服务端完成验证)
- keystone验证token成功之后,将token对应用户的详细信息,例如:role,username,userid等,返回给服务端(nova)。
- 服务端(nova)完成请求,例如:创建虚拟机。
- 服务端返回请求结果给alice。
2.glance
v1

OpenStack从入门到放弃
v2

OpenStack从入门到放弃
3.nova与cinder
nova主要组成:
nova-api
nova-scheduler
nova-compute
nova-conductor
cinder主要组成:
cinder-api
cinder-scheduler
cinder-volume
cinder各组件功能:
Cinder-api 是 cinder 服务的 endpoint,提供 rest 接口,负责处理 client 请求,并将 RPC 请求发送至 cinder-scheduler 组件。
Cinder-scheduler 负责 cinder 请求调度,其核心部分就是 scheduler_driver, 作为 scheduler manager 的 driver,负责 cinder-volume 具体的调度处理,发送 cinder RPC 请求到选择的 cinder-volume。
Cinder-volume 负责具体的 volume 请求处理,由不同后端存储提供 volume 存储空间。目前各大存储厂商已经积极地将存储产品的 driver 贡献到 cinder 社区
cinder架构图:

OpenStack从入门到放弃
openstack组件间通信:调用各组件api提供的rest接口,组件内通信:基于rpc(远程过程调用)机制,而rpc机制是基于AMQP模型实现的
从rpc使用的角度出发,nova,neutron,和cinder的流程是相似的,我们以cinder为例阐述rpc机制
(参考链接:https://www.ibm.com/developerworks/cn/cloud/library/1403_renmm_opestackrpc/)
Openstack 组件内部的 RPC(Remote Producer Call)机制的实现是基于 AMQP(Advanced Message Queuing Protocol)作为通讯模型,从而满足组件内部的松耦合性。AMQP 是用于异步消息通讯的消息中间件协议,AMQP 模型有四个重要的角色:
Exchange:根据 Routing key 转发消息到对应的 Message Queue 中
Routing key:用于 Exchange 判断哪些消息需要发送对应的 Message Queue
Publisher:消息发送者,将消息发送的 Exchange 并指明 Routing Key,以便 Message Queue 可以正确的收到消息
Consumer:消息接受者,从 Message Queue 获取消息
消息发布者 Publisher 将 Message 发送给 Exchange 并且说明 Routing Key。Exchange 负责根据 Message 的 Routing Key 进行路由,将 Message 正确地转发给相应的 Message Queue。监听在 Message Queue 上的 Consumer 将会从 Queue 中读取消息。
Routing Key 是 Exchange 转发信息的依据,因此每个消息都有一个 Routing Key 表明可以接受消息的目的地址,而每个 Message Queue 都可以通过将自己想要接收的 Routing Key 告诉 Exchange 进行 binding,这样 Exchange 就可以将消息正确地转发给相应的 Message Queue。
Publisher可以分为4类:
Direct Publisher发送点对点的消息;
Topic Publisher采用“发布——订阅”模式发送消息;
Fanout Publisher发送广播消息的发送;
Notify Publisher同Topic Publisher,发送 Notification 相关的消息。
Exchange可以分为3类:
1.Direct Exchange根据Routing Key进行精确匹配,只有对应的 Message Queue 会接受到消息;
2.Topic Exchange根据Routing Key进行模式匹配,只要符合模式匹配的Message Queue都会收到消息;
3.Fanout Exchange将消息转发给所有绑定的Message Queue。
AMQP消息模型

OpenStack从入门到放弃
RPC 发送请求
Client 端发送 RPC 请求由 publisher 发送消息并声明消息地址,consumer 接收消息并进行消息处理,如果需要消息应答则返回处理请求的结果消息。
OpenStack RPC 模块提供了 rpc.call,rpc.cast, rpc.fanout_cast 三种 RPC 调用方法,发送和接收 RPC 请求。
1.rpc.call 发送 RPC 请求并返回请求处理结果,请求处理流程如图 5 所示,由 Topic Publisher 发送消息,Topic Exchange 根据消息地址进行消息转发至对应的 Message Queue 中,Topic Consumer 监听 Message Queue,发现需要处理的消息则进行消息处理,并由 Direct Publisher 将请求处理结果消息,请求发送方创建 Direct Consumer 监听消息的返回结果
2.rpc.cast 发送 RPC 请求无返回,请求处理流程如图 6 所示,与 rpc.call 不同之处在于,不需要请求处理结果的返回,因此没有 Direct Publisher 和 Direct Consumer 处理。
3.rpc.fanout_cast 用于发送 RPC 广播信息无返回结果
4.neutron
neutron包含组件:
neutron-server
neutron-plugin
neutron-agent
neutron各组件功能介绍:
1.Neutron-server可以理解为一个专门用来接收Neutron REST API调用的服务器,然后负责将不同的rest api分发到不同的neutron-plugin上。
2.Neutron-plugin可以理解为不同网络功能实现的入口,各个厂商可以开发自己的plugin。Neutron-plugin接收neutron-server分发过来的REST API,向neutron database完成一些信息的注册,然后将具体要执行的业务操作和参数通知给自身对应的neutron agent。
3.Neutron-agent可以直观地理解为neutron-plugin在设备上的代理,接收相应的neutron-plugin通知的业务操作和参数,并转换为具体的设备级操作,以指导设备的动作。当设备本地发生问题时,neutron-agent会将情况通知给neutron-plugin。
4.Neutron database,顾名思义就是Neutron的数据库,一些业务相关的参数都存在这里。
5.Network provider,即为实际执行功能的网络设备,一般为虚拟交换机(OVS或者Linux Bridge)。
neutron-plugin分为core-plugin和service-plugin两类。
Core-plugin,Neutron中即为ML2(Modular Layer 2),负责管理L2的网络连接。ML2中主要包括network、subnet、port三类核心资源,对三类资源进行操作的REST API被neutron-server看作Core API,由Neutron原生支持。其中:

OpenStack从入门到放弃
Service-plugin,即为除core-plugin以外其它的plugin,包括l3 router、firewall、loadbalancer、VPN、metering等等,主要实现L3-L7的网络服务。这些plugin要操作的资源比较丰富,对这些资源进行操作的REST API被neutron-server看作Extension API,需要厂家自行进行扩展。
“Neutron对Quantum的插件机制进行了优化,将各个厂商L2插件中独立的数据库实现提取出来,作为公共的ML2插件存储租户的业务需求,使得厂商可以专注于L2设备驱动的实现,而ML2作为总控可以协调多厂商L2设备共同运行”。在Quantum中,厂家都是开发各自的Service-plugin,不能兼容而且开发重复度很高,于是在Neutron中就为设计了ML2机制,使得各厂家的L2插件完全变成了可插拔的,方便了L2中network资源扩展与使用。
(注意,以前厂商开发的L2 plugin跟ML2都存在于neutron/plugins目录下,而可插拔的ML2设备驱动则存在于neutron/plugins/ml2/drivers目录下)
ML2作为L2的总控,其实现包括Type和Mechanism两部分,每部分又分为Manager和Driver。Type指的是L2网络的类型(如Flat、VLAN、VxLAN等),与厂家实现无关。Mechanism则是各个厂家自己设备机制的实现,如下图所示。当然有ML2,对应的就可以有ML3,不过在Neutron中L3的实现只负责路由的功能,传统路由器中的其他功能(如Firewalls、LB、VPN)都被独立出来实现了,因此暂时还没有看到对ML3的实际需求。

OpenStack从入门到放弃
一般而言,neutron-server和各neutron-plugin部署在控制节点或者网络节点上,而neutron agent则部署在网络节点上和计算节点上。我们先来分析控制端neutron-server和neutron-plugin的工作,然后再分析设备端neutron-agent的工作。
neutron新进展(dragon flow):
https://www.ustack.com/blog/neutron-dragonflow/
网络模式介绍:
根据创建网络的用户的权限,Neutron network 可以分为:
- Provider network:管理员创建的和物理网络有直接映射关系的虚拟网络。
- Tenant network:租户普通用户创建的网络,物理网络对创建者透明,其配置由 Neutorn 根据管理员在系统中的配置决定。
根据网络的类型,Neutron network 可以分为:
- VLAN network(虚拟局域网) :基于物理 VLAN 网络实现的虚拟网络。共享同一个物理网络的多个 VLAN 网络是相互隔离的,甚至可以使用重叠的 IP 地址空间。每个支持 VLAN network 的物理网络可以被视为一个分离的 VLAN trunk,它使用一组独占的 VLAN ID。有效的 VLAN ID 范围是 1 到 4094。
- Flat network:基于不使用 VLAN 的物理网络实现的虚拟网络。每个物理网络最多只能实现一个虚拟网络。
- local network(本地网络):一个只允许在本服务器内通信的虚拟网络,不知道跨服务器的通信。主要用于单节点上测试。
- GRE network (通用路由封装网络):一个使用 GRE 封装网络包的虚拟网络。GRE 封装的数据包基于 IP 路由表来进行路由,因此 GRE network 不和具体的物理网络绑定。
- VXLAN network(虚拟可扩展网络):基于 VXLAN 实现的虚拟网络。同 GRE network 一样, VXLAN network 中 IP 包的路由也基于 IP 路由表,也不和具体的物理网络绑定。
注:在AWS中,该概念对应 VPC 概念。AWS 对 VPC 的数目有一定的限制,比如每个账户在每个 region 上默认最多只能创建 5 个VPC,通过特别的要求最多可以创建 100 个。
1.vlan

OpenStack从入门到放弃

OpenStack从入门到放弃
2.gre与vxlan请参考
http://www.cnblogs.com/sammyliu/p/4622563.html
http://www.cnblogs.com/xingyun/p/4620727.html
gre网络

OpenStack从入门到放弃
gre与vxlan区别

OpenStack从入门到放弃
关于gre和vxlan二次封装数据包的MTU问题
VXLAN 模式下虚拟机中的 mtu 最大值为1450,也就是只能小于1450,大于这个值会导致 openvswitch 传输分片,进而导致虚拟机中数据包数据重传,从而导致网络性能下降。GRE 模式下虚拟机 mtu 最大为1462。
计算方法如下:
- vxlan mtu = 1450 = 1500 – 20(ip头) – 8(udp头) – 8(vxlan头) – 14(以太网头)
- gre mtu = 1462 = 1500 – 20(ip头) – 4(gre头) – 14(以太网头)
可以配置 Neutron DHCP 组件,让虚拟机自动配置 mtu,
#/etc/neutron/dhcp_agent.ini [DEFAULT] dnsmasq_config_file = /etc/neutron/dnsmasq-neutron.conf#/etc/neutron/dnsmasq-neutron.conf dhcp-option-force=26,1450或1462
重启 DHCP Agent,让虚拟机重新获取 IP,然后使用 ifconfig 查看是否正确配置 mtu。

 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战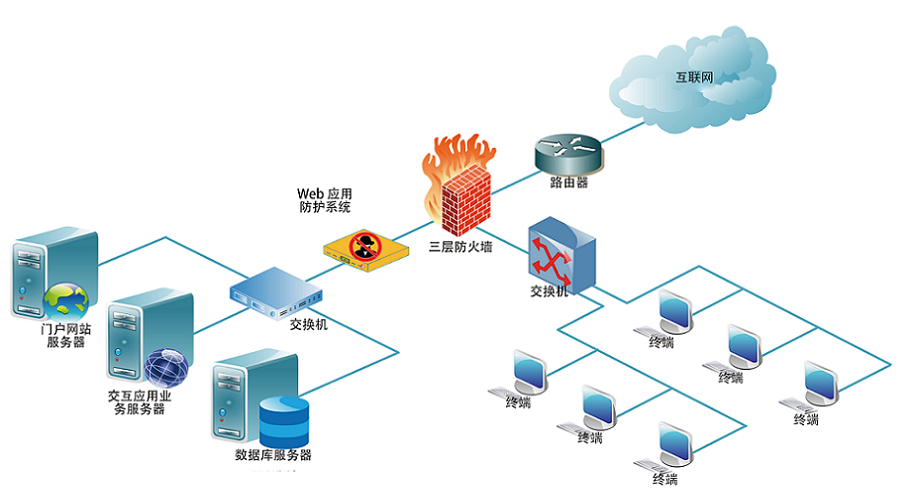 WEB架构
WEB架构 安全监控体系
安全监控体系