Hive
Hive由facebook贡献给Apache,是一款建立在Hadoop之上的数据仓库的基础框架。
数据仓库
特点——关于存放在数据仓库中的数据的说明:
是能够为企业的各个级别的决策提供数据支撑的数据
其实说白了,就是一个存放数据的仓库
数据库和数据仓库之间的区别
现代数据仓库,是构建在数据库之上的,使用数据库作为载体存放数据。
数据仓库着重强调的是存放的历史数据,数据库着重强调的是存放在线的数据。
数据仓库着重强调的是OLAP的操作,数据库着重强调的是OLTP的操作
OLAP:Online Analysis Processing 联机分析处理--->对数据进行分析查询select、load
OLTP:Online Transcation Processing 联机事务处理--->对数据进行事务性操作update delete
数据仓库操作的都是历史数据,数据库操作的几乎都是在线交易数据
#ETL—是用来构建我们一个数据仓库的概念
E(Extract 提取) 获取数据的过程,就称之为提取,采集
T(Transform 转化) 对进入仓库的数据进行分类、清洗
L(Load 加载) 数据进入仓库的过程就是Load
BI(Business Intelligence)
Hive是一款SQL的解析引擎,能够将HQL转移成为MR在hadoop计算hdfs上面的数据。
#介绍
存储结构
Hive的数据存储基于Hadoop HDFS
Hive没有专门的数据存储格式
存储结构主要包括:数据库、文件、表、视图、索引
Hive默认可以直接加载文本文件(TextFile),还支持SequenceFile、RCFile 、ORCFile、Parquet
创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据
系统架构
用户接口:包括 CLI,JDBC/ODBC,WebUI
元数据存储:通常是存储在关系数据库如 mysql, derby等等中
Driver:解释器、编译器、优化器、执行器
Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算
Hive的安装
三个前提
JDK
HADOOP
MySQL
也就是确保上面三步都安装完成后再安装Hive
第一步:安装MySQL(离线)
操作目录:/home/uplooking/soft --->安装包所在目录
1°、查询linux中已有的mysql依赖包
[uplooking@uplooking01 ~]$ rpm -qa | grep mysql mysql-libs-5.1.71-1.el6.x86_64
2°、删除linux中已有的mysql依赖包
[uplooking@uplooking01 ~]$ sudo rpm -e --nodeps `rpm -qa | grep mysql`
3°、安装服务端和客户端
[uplooking@uplooking01 ~]$ sudo rpm -ivh soft/MySQL-server-5.5.45-1.linux2.6.x86_64.rpm
[uplooking@uplooking01 ~]$ sudo rpm -ivh soft/MySQL-client-5.5.45-1.linux2.6.x86_64.rpm
4°、启动mysql server服务
[uplooking@uplooking01 ~]$ sudo service mysql start(注意:离线安装后mysql的服务名称为mysql,在线安装后的服务名称为msyqld)
5°、加入到开机启动项
[uplooking@uplooking01 ~]$ sudo chkconfig mysql on
6°、进行用户名密码设置
[uplooking@uplooking01 ~]$ sudo /usr/bin/mysql_secure_installation
7°、对远程可访问的机器进行授权
uplooking@uplooking01 ~]$ mysql -huplooking01 -uroot -puplooking
ERROR 1130 (HY000): Host 'uplooking01' is not allowed to connect to this MySQL server
在mysql服务器登录:mysql -uroot -puplooking
执行以下语句:
mysql> grant all privileges on *.* to 'root'@'%' identified by 'uplooking';
mysql> flush privileges;
第二步:安装Hive
1°、解压Hive文件:
进入$HIVE_HOME/conf/修改文件
cp hive-env.sh.template hive-env.sh
cp hive-default.xml.template hive-site.xml
2°、修改$HIVE_HOME/bin的hive-env.sh,增加以下三行
export JAVA_HOME=/opt/jdk
export HADOOP_HOME=/home/uplooking/app/hadoop
export HIVE_HOME=/home/uplooking/app/hive
3°、修改$HIVE_HOME/conf/hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://uplooking01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>uplooking</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/home/uplooking/app/hive/tmp</value>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/uplooking/app/hive/tmp</value>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/uplooking/app/hive/tmp</value>
</property>
4°、拷贝mysql驱动jar包到$HIVE_HOME/lib下面
[uplooking@uplooking01 hive]$ cp ~/soft/mysql-connector-java-5.1.39.jar lib/
5°、初始化hive元数据仓库
该执行目录$HIVE_HOME/bin
bin]$ ./schematool -initSchema -dbType mysql -userName root -passWord uplooking
6°、启动hive
./hive
Hive的访问
有本地运行模式和集群运行模式
本地模式需要打开开关:set hive.exec.mode.local.auto=true
默认是集群模式
本地模式在对sql进行调试,测试的时候经常使用
<property>
<name>hive.exec.mode.local.auto</name>
<value>false</value>
<description>Let Hive determine whether to run in local mode automatically</description>
</property>
<property>
<name>hive.exec.mode.local.auto.inputbytes.max</name>
<value>134217728</value>//128M
<description>When hive.exec.mode.local.auto is true, input bytes should less than this for local mode.</description>
</property>
<property>
<name>hive.exec.mode.local.auto.input.files.max</name>
<value>4</value>
<description>When hive.exec.mode.local.auto is true, the number of tasks should less than this for local mode.</description>
</property>
有CLI、WebGUI、JDBC的三种访问方式
CLI是最常用,也就是命令行模式
WebGUI需要自己通过hive源码制作一个war,部署到hive里面,才能够使用其提供的一个web界面来访问hive,进行相关操作
JDBC就是进行sql编程,如果hive使用的是MR的计算引擎,则其运行非常之慢,不能作为交互式查询
hive目前支持三种计算引擎:mr、spark、tez,默认是mr,spark在hive-2.0以后的版本才支持
<property>
<name>hive.execution.engine</name>
<value>mr</value>
</property>
Hive基本操作
数据库操作
创建数据库:
create database mydb1;
使用数据库:
use mydb1;
显示当前正在使用的数据库:
set hive.cli.print.current.db=true;
显示数据库列表:
show databases;
删除:
drop database mydb1;
表操作
表的数据类型,除了string和复合数据类型(array, map, struct)之外,几乎和mysql一致。
DDL
DDL即数据库模式定义语言DDL(Data Definition Language),用于描述数据库中要存储的现实世界实体的语言,其实说白了就是数据库中关于表操作的语句。
表的创建
create table 表名(
字段名 字段类型 注解comment, ... ,
字段名 字段类型 注解comment
) comment "";
eg.
create table t1(
id int,
name string comment "this is t1's column name"
) comment "TABLE t1";
增加一列:
alter table t1 add columns (age int) ;
删除一列?不支持删除一列
alter table t1 drop column age;
替换,曲线完成删除一列的内容
alter table t1 replace columns(online string);使用当前列替换掉原有的所有列
工作中,经常使用脚本的方式来对编写,并执行hql:
hive客户端:hive> source /opt/data/hive/hive-t1.hql;
linux终端一:/opt/hive/bin/hive -f hive-t1-1.hql
linux终端二:/opt/hive/bin/hive -e "set hive.exec.mode.local.auto=true;select * from test;"
对上述linux终端的执行方式,我们还可以添加相关参数选项
/opt/hive/bin/hive -f hive-t1-1.hql --hiveconf hive.exec.mode.local.auto=true
/opt/hive/bin/hive -e "select * from test;" --hiveconf hive.exec.mode.local.auto=true
这样做,可以非常方便将hive的执行语句,组成成为shell脚本,在linux中调度相关shell计算hive中的数据
这两个-e和-f不能互换,
eg。
/opt/hive/bin/hive -e "use mydb1; select * from test where line like '%you%';" --hiveconf hive.cli.print.header=true
/opt/hive/bin/hive -f hive-t1-1.hql --hiveconf hive.cli.print.header=true
数据操作
向hive表中导入数据的方式
hive cli:
hive> load data local inpath '/opt/data/hive/hive-t1-1.txt' into table t1;
Linux终端:
$ hdfs dfs -put /opt/data/hive/hive-t1-1.txt /user/hive/warehouse/t1/
我们在导入数据的时候,发现数据没有解析成功,那是因为自定义的数据,行列有相关的分隔符,并没有告知当前表如何解析,或者说自定义数据的解析方式和hive表的默认的解析方式不一致。
hive表默认的解析方式—-行列的分隔符
默认的行分隔符\n
默认的列分隔符\001 在键盘上如何输入呢ctrl+v ctrl+a
数据进入数据库表中的模式
读模式
将数据加载到表中的时候,对数据的合法性不进行校验,只有在操作表的时候,才对数据合法性进行校验,不合法的数据显示为NULL(比如某一列的数据类型为日期类型,如果load的某条数据是该列不是日期类型,则该条数据的这一列不合法,导入hive之后就会显示为NULL)
适合大数据的加载,比如hive
写模型
在数据加载到表中的时候,需要对数据的合法性进行校验,加载到数据库中的数据,都是合法的数据。
适合事务性数据库加载数据,常见的mysql、oracle等都是采用这种模式
自定义分隔符
create table t2 (
id int,
name string,
birthday date,
online boolean
) row format delimited ---->开启使用自定义分隔符的标识
fields terminated by '\t' ---->对每一列分隔符的定义
lines terminated by '\n'; ---->对每一行分隔符的定义,当然可以省略不写,默认和linux保持一致,同时注意,这两个顺序不能颠倒
Hive表的复合数据类型
array —->java中的array
create table t3_arr(
id int,
name string,
hobby array<string>
)
row format delimited
fields terminated by '\t';
array的默认分割是\002,在shell中如何敲出来ctrl+v ctrl+b
默认不能满足需求,需要自定义分隔符
create table t3_arr_1(
id int,
name string,
hobby array<string>
)
row format delimited
fields terminated by '\t'
collection items terminated by ',';
在导入数据时,数据的格式应该如下:
1 香飘叶子 IT,Computer
array的引用,使用arrayName[index],索引从0开始
map—->java中的map
每个人都有学习(语文、数学、体育)成绩
create table t4_map(
id int,
name string,
score map<string, float> comment "this is score"
) row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by '=';
根据上面的定义,导入的数据格式应该如下:
1 香飘叶子 Chinese=102,Math=121,English=124
map里面的默认的key和value之间的分隔符:\003,在shell里面通过ctrl+v ctrl+c
map具体值的调用格式,列名["属性"],比如score["chinese"]
struct—->java中的object
id name address(province:string, city:string, zip:int)
1 小陈 bj,chaoyang,100002
2 老王 hb,shijiazhuang,052260
3 小何 hn,huaiyang,466000
4 小马 hlj,harbin,10000
create table t5_struct (
id int,
name string,
address struct<province:string, city:string, zip:int>
) row format delimited
fields terminated by '\t'
collection items terminated by ',';
调用的格式:列名.属性,比如address.province
复合数据类型案例
有一张员工表:
id int
name string
subordinate array<int>
salary float
tax map<string, float>
home_info struct<province:string, city:string, zip:int>
创建表:
create table t7_emp (
id int,
name string,
subordinate array<int>,
salary float,
tax map<string, float>,
home_info struct<province:string, city:string, zip:int>
);
查询员工的税后工资,查询家乡为河北的人员:
select id, name, salary * (1 - tax["gs"] - tax["gjj"] - tax["sb"]) sh_salary from t7_emp where home_info.province = "河北";

 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战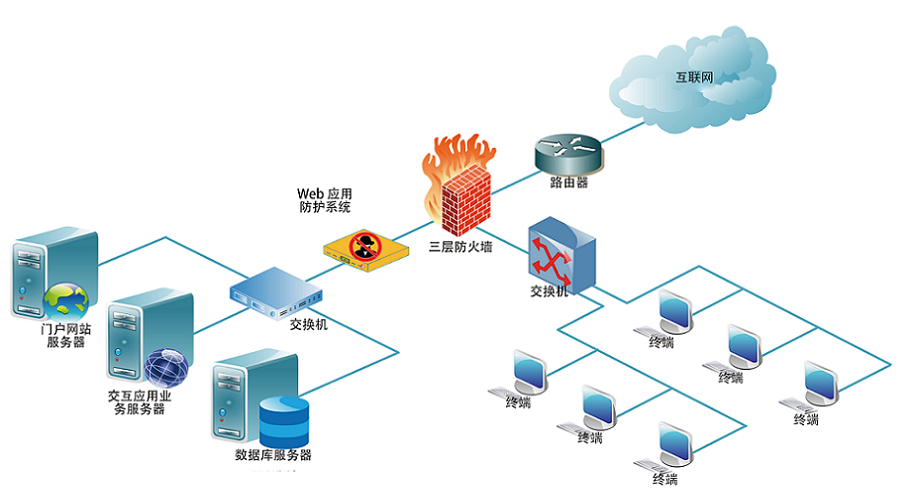 WEB架构
WEB架构 安全监控体系
安全监控体系