
pipeline流水线编写推荐使用声明式
可以按我以下的模板套路来编写,接下来我也举一些例子
#!groovy
string workspace = "/opt/jenkins/wordspace" // 自定义工作目录
pipeline {
// ========agent语句块开始========
agent {
node {
label "master" // 指定运行节点的标签或者名称
customWorkspace "${workspace}" // 自定义工作目录,调用上面的变量(可选)
}
}
// ======agent块结束======
options { // 运行选项按需指定,不是必须的
timestamps() // 日志会有时间,便于排查日志
skipDefaultCheckout() //删除隐式checkout scm语句,声明式的脚本默认会去检查有没有配代码库,如果有的话会自动下载代码,但我没有必要去让他下载,所以这里删除
disableConcurrentBuilds() // 禁止并行,根据项目需要,有些项目是不能并行的,可以使用这句。
timeout(time: 1, unit: 'HOURS') // 设置流水线超时时间,在企业中使用流水线时会遇到很多构建超时了,一直卡在那里,一直失败,这样会消耗很多资源,占用构建队列,导致构建队列出现堵塞这种情况,所以这里设置一小时超时,这个时间已经很长了。
}
// ===========options语句块结束==========
// ============stages语句块开始《一个或多个》====================
stages {
stage("GetCode"){ // 这是第一个小阶段的名称
steps{ // 步骤
timeout(time:5,unit:"MINUTES"){ // 步骤超时时间
script{ // 填写运行代码
println("获取代码")
}
}
}
}
// 第一个小阶段结束
stage("Build"){
steps{
timeout(time:20, unit:"MINUTES"){
script{
println("应用打包")
}
}
}
}
// 第二个小阶段结束
stage("CodeScan"){
steps{
timeout(time:30, unit:"MINUTES"){
script{
print("代码扫描")
}
}
}
}
// 第三个小阶段结束
}
// ======================stages阶段结束================
// ===============构建后执行post===================
post {
// always指不管结果如何都执行
always {
script{
println("always")
}
}
// always语句块结束
// success指构建成功才会执行,一般在企业中可能会触发一个状态作一个变更
success {
script{
currentBuild.description += "\n 构建成功!" // currentBuild是一个全局变量,description是构建描述
}
}
// success语句块结束
// failure指构建失败时执行,例如通知管理员
failure {
script{
currentBuild.description += "\n 构建失败!"
}
}
// failure语句块结束
// aborted指任务取消时执行,一般也会做一个通知,和构建失败的对待方式差不多,如果有什么资源需要回收的可以写在这里
aborted {
script{
currentBuild.description += "\n 构建取消"
}
}
// aborted语句块结束
}
// ================post语句结束=======================
}


 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战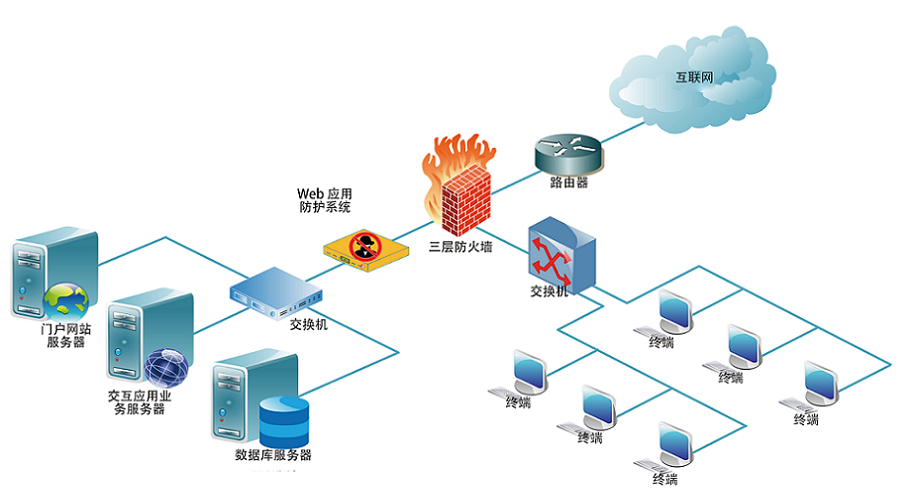 WEB架构
WEB架构 安全监控体系
安全监控体系





post {
always {
script{
if (currentBuild.currentResult == "ABORTED" || currentBuild.currentResult == "FAILURE" || currentBuild.currentResult == "UNSTABLE" ){
slackSend channel: "#机器人", message: "Build failure: ${env.JOB_NAME} -- No: ${env.BUILD_NUMBER}, please check detail in email!"
} else {
slackSend channel: "#机器人", message: "Build Success: ${env.JOB_NAME} -- Build No: ${env.BUILD_NUMBER}, please check on http://www.yourwebsite.com"
}
}
}
}
可以这样改写:
["ABORTED", "FAILURE", "UNSTABLE"].contains(currentBuild.currentResult)根据 pipeline 或阶段的完成状态,post 部分分成多种条件块,包括:
• always:不论当前完成状态是什么,都执行。
• changed:只要当前完成状态与上一次完成状态不同就执行。
• fixed:上一次完成状态为失败或不稳定(unstable),当前完成状态为成功时执行。
• regression:上一次完成状态为成功,当前完成状态为失败、不稳定或中止(aborted)时执行。
• aborted:当前执行结果是中止状态时(一般为人为中止)执行。
• failure:当前完成状态为失败时执行。
• success:当前完成状态为成功时执行。
• unstable:当前完成状态为不稳定时执行。
• cleanup:清理条件块。不论当前完成状态是什么,在其他所有条件块执行完成后都执行。post部分可以同时包含多种条件块。