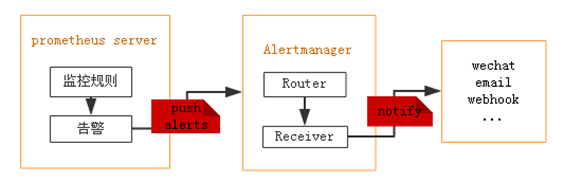
Prometheus本身不支持告警功能,主要通过插件alertmanage来实现告警。AlertManager用于接收Prometheus发送的告警并对于告警进行一系列的处理后发送给指定的用户。
Prometheus触发一条告警的过程:
prometheus—>触发阈值—>超出持续时间—>alertmanager—>分组|抑制|静默—>媒体类型—>邮件|钉钉|微信等。
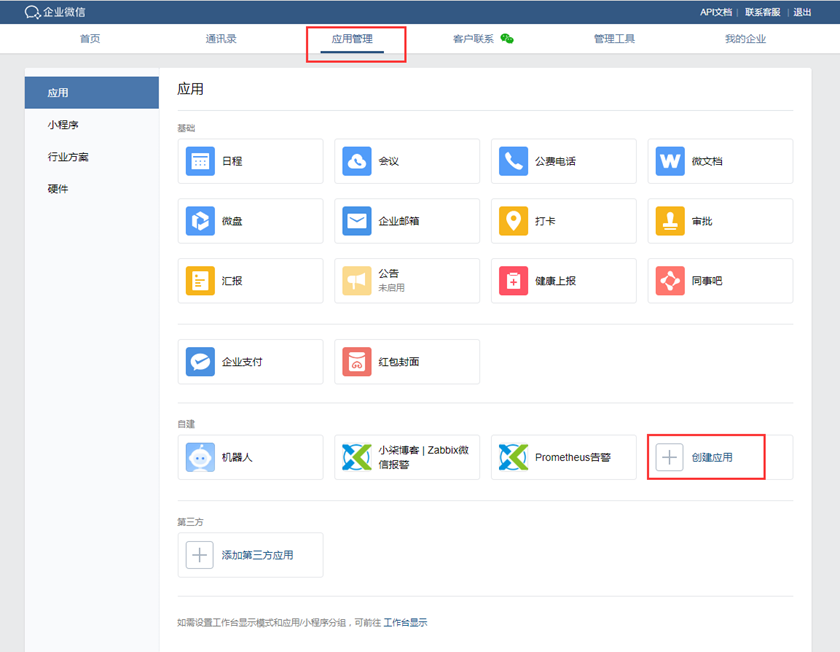
实现WeChat告警-准备工作
1、访问企业微信官网(https://work.weixin.qq.com/),注册企业微信账号(不需要企业认证)。
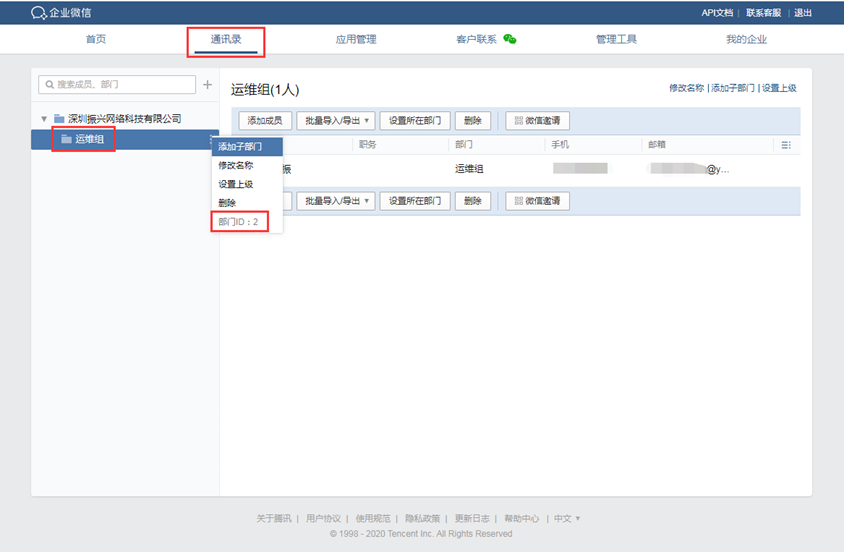
2、登录成功后—>>应用管理—>>创建第三方应用,点击创建应用按钮 -> 填写应用信息:
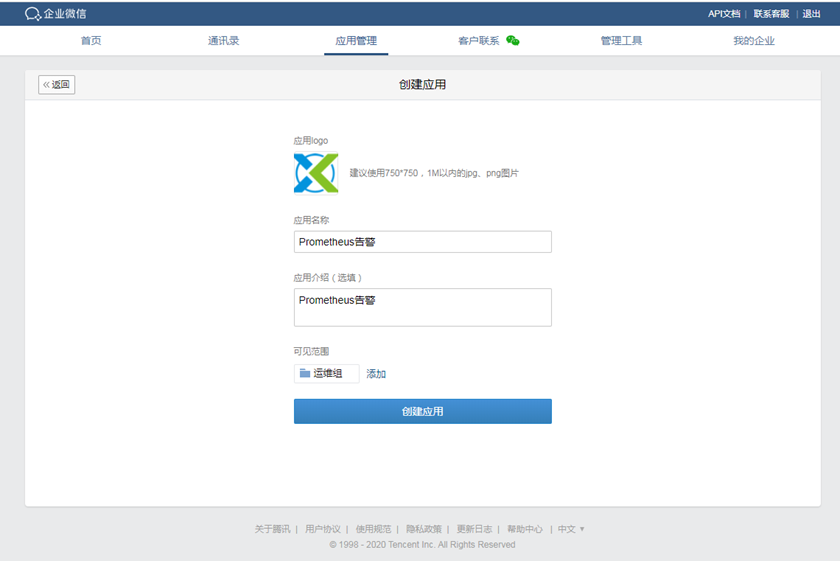
填写应用信息:
部门ID:to_party 需要发送的组
安装Alertmanager
1、下载Alertmanager
wget https://github.com/prometheus/alertmanager/releases/download/v0.20.0/alertmanager-0.20.0.linux-amd64.tar.gz
tar xf alertmanager-0.20.0.linux-amd64.tar.gz
mv alertmanager-0.20.0.linux-amd64 /usr/local/alertmanager2、创建启动文件
vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
Documentation=https://github.com/prometheus/alertmanager
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target3、配置alertmanager.yml文件
Alertmanager 安装目录下默认有 alertmanager.yml 配置文件,可以创建新的配置文件,在启动时指定即可。
cd /usr/local/alertmanager
vim alertmanager.yml
global:
# 每2分钟检查一次是否恢复
resolve_timeout: 2m
# 自定义通知模板
templates:
- '/usr/local/prometheus/alertmanager/template/wechat.tmpl'
# route用来设置报警的分发策略
route:
# 采用哪个标签来作为分组依据
group_by: ['alertname']
# 组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出
group_wait: 10s
# 两组告警的间隔时间
group_interval: 10s
# 重复告警的间隔时间,减少相同微信告警的发送频率
repeat_interval: 1h
# 设置默认接收人
receiver: 'wechat'
routes: # 可以指定哪些组接手哪些消息
- receiver: 'wechat'
continue: true
group_wait: 10s
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'xxx'
to_party: '2'
agent_id: 'xxx'
api_secret: 'xxx'
send_resolved: true参数说明:
corp_id: 企业微信账号唯一 ID, 可以在我的企业中查看。
to_party: 需要发送的组。
agent_id: 第三方企业应用的 ID,可以在自己创建的第三方企业应用详情页面查看。
api_secret: 第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
4、配置告警模板
mkdir -p /usr/local/prometheus/alertmanager/template
vim /usr/local/prometheus/alertmanager/template/wechat.tmpl
# 只告警,恢复后不发送消息
{{ define “wechat.default.message” }}
{{ range .Alerts }}
========start==========
告警程序:prometheus_alert
告警级别:{{ .Labels.severity }}
告警类型:{{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ .StartsAt.Format “2020-4-16 15:55:36” }}
========end==========
{{ end }}
{{ end }}
# 带恢复告警的模版 注:需要在alertmanager.yml的wechat_configs中加上配置send_resolved: true
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
===alertmanager监控报警===
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
告警应用:{{ $alert.Annotations.summary }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
触发阀值:{{ $alert.Annotations.value }}
告警详情: {{ $alert.Annotations.description }}
触发时间: {{ $alert.StartsAt.Format “2020-4-16 15:55:19” }}
===========end============
{{ end }}
{{ end }}精简版
{{ define "wechat.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
@警报
实例: {{ .Labels.instance }}
信息: {{ .Annotations.summary }}
详情: {{ .Annotations.description }}
时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
@恢复
实例: {{ .Labels.instance }}
信息: {{ .Annotations.summary }}
时间: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{ end }}{{ end -}}
{{- end }}{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 异常恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}只有告警的极简版
{{ define "wechat.default.message" }}
{{ range .Alerts }}
========start=========
告警程序: prometheus_alert
告警级别: {{ .Labels.serverity }}
告警类型: {{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
告警主题: {{ .Annotations.summary }}
告警详情: {{ .Annotations.description }}
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }}
=========end===========
{{ end }}
{{ end }}K8S环境
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
==========异常告警==========
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};{{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
============END============
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
==========异常恢复==========
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};{{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
============END============
{{- end }}
{{- end }}
{{- end }}
{{- end }}5、配置告警规则
mkdir -p /usr/local/prometheus/rules
cd /usr/local/prometheus/rules
vim node.yml
groups:
- name: Node_Down
rules:
- alert: Node实例已宕机
expr: up == 0
for: 10s
labels:
user: root
severity: Warning
annotations:
summary: "Instance {{ $labels.instance }} Down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been Down."在Prometheus.yml中指定node.yml的路径
vim /usr/local/prometheus/prometheus.yml
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['localhost:9093']
# - localhost:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- 'rules/node.yml'
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9100']6、重启Prometheus服务
systemctl restart prometheus7、启动Alertmanager
systemctl daemon-reload
systemctl start alertmanager8、验证效果
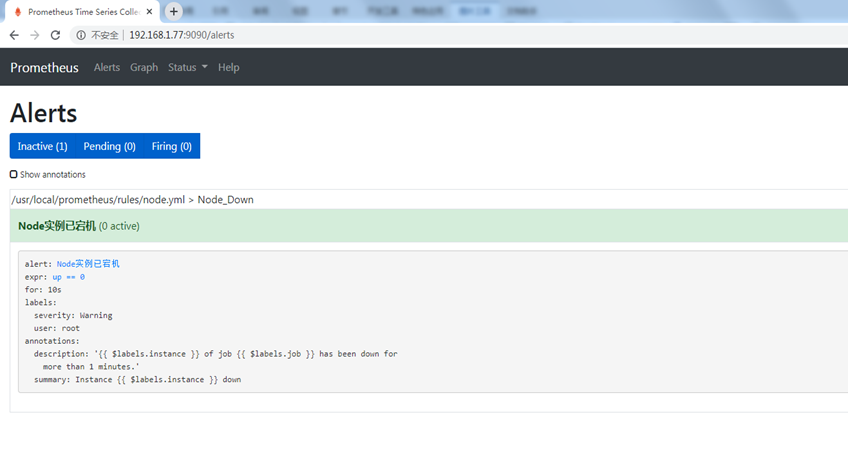
此时访问prometheus管理界面可以看到如下信息:
9、然后停止 node_exporter 服务,然后再看效果。
systemctl stop node_exporterprometheus界面的alert可以看到告警状态。
绿色表示正常。
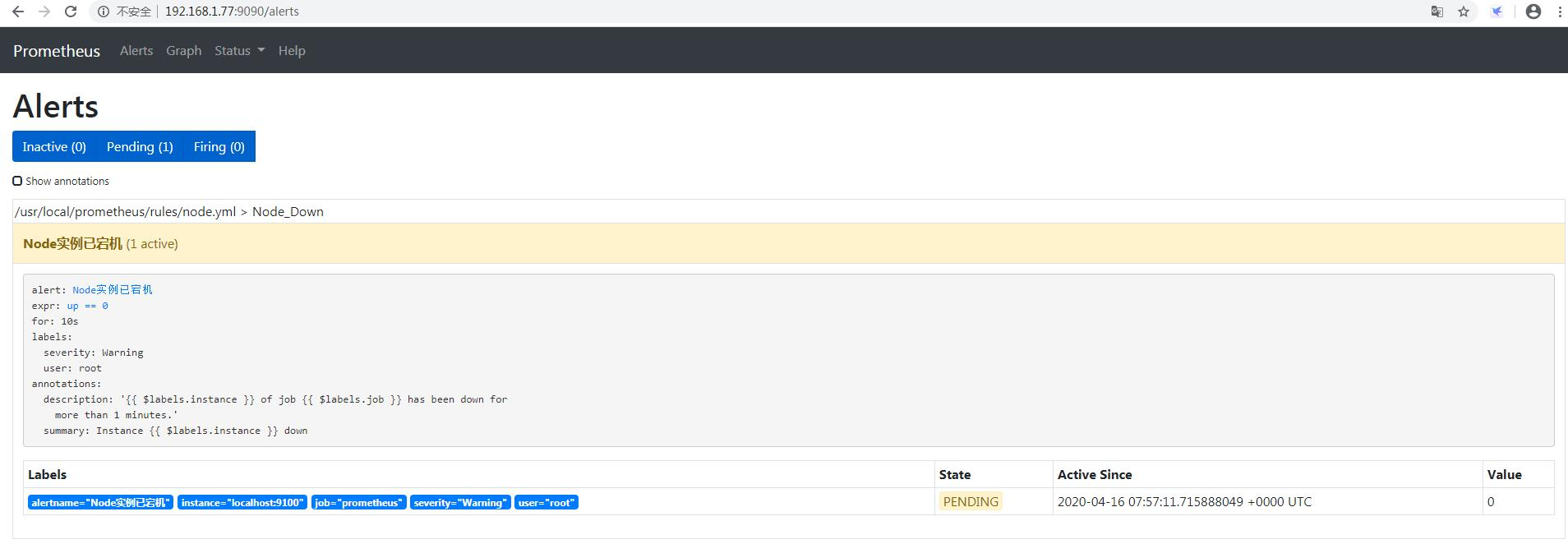
红色状态为PENDING表示alerts还没有发送至Alertmanager,因为rules里面配置了for: 10s。
10秒后状态由PENDING变为FIRING,此时Prometheus才将告警发给alertmanager,在Alertmanager中可以看到有一个alert。
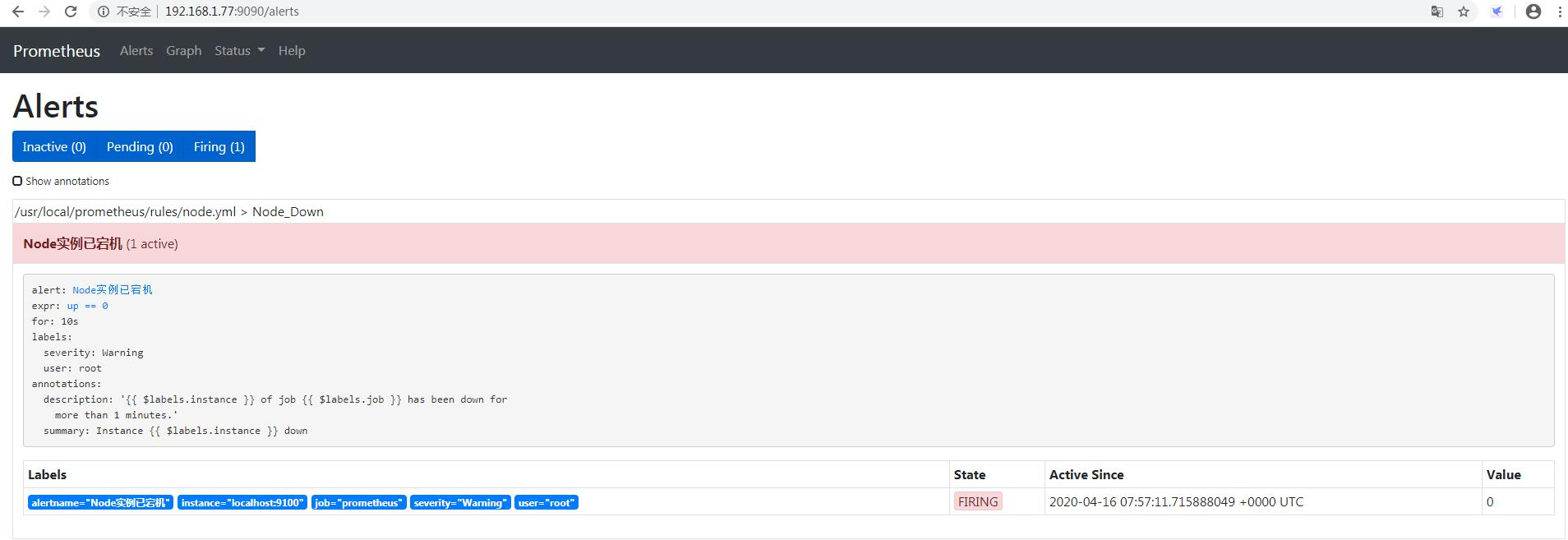
10、接着企业微信会收到告警信息
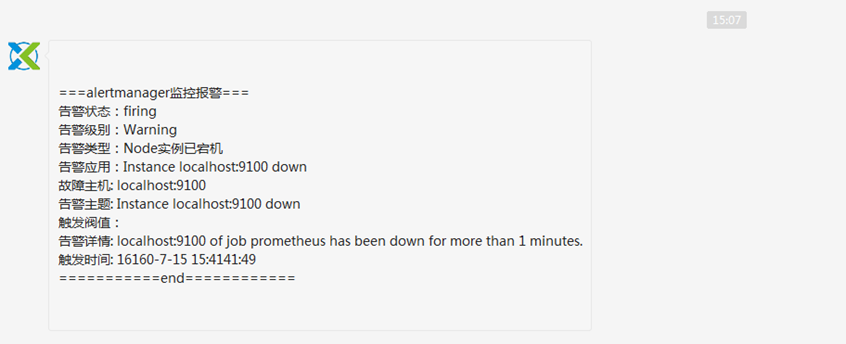
11、再次启动node_export
systemctl start node_exporter企业微信会收到恢复信息
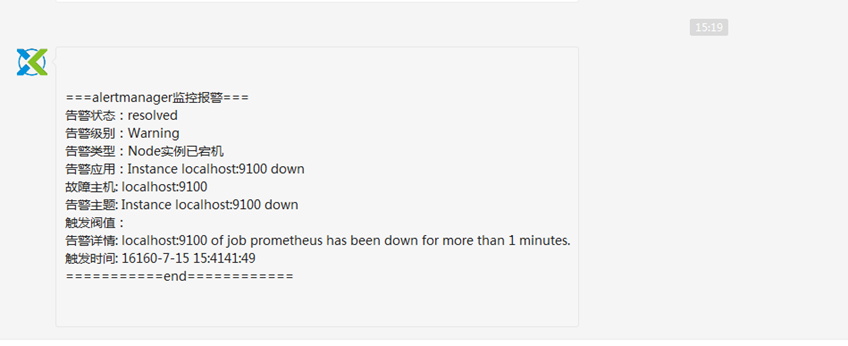
CPU使用率告警规则:
groups:
- name: CPU
rules:
- alert: CPU使用率过高
expr: (100 - (avg by (instance) (irate(node_cpu{mode="idle"}[5m])) * 100)) > 80
for: 1m
labels:
severity: Warning
annotations:
summary: "{{ $labels.instance }} CPU使用率过高"
description: "{{ $labels.instance }}: CPU使用率超过80%,当前使用率({{ $value }})."内存使用率告警规则:
groups:
- name: Memory
rules:
- alert: 内存使用率过高
expr: (node_memory_MemTotal - (node_memory_MemFree+node_memory_Buffers+node_memory_Cached )) / node_memory_MemTotal * 100 > 80
for: 1m #告警持续时间,超过这个时间才会发送给alertmanager
labels:
severity: Warning
annotations:
summary: "{{ $labels.instance }} 内存使用率过高"
description: "{{ $labels.instance }}:内存使用率超过80%,当前使用率({{ $value }})."


 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系