前面我们学习了client-gohttps://docs.ct99.cn/web/#/186/1519,知道如何用client-go来实现的一个控制器,但是我们前面介绍的都是 Kubernetes 中内置的资源对象,比如 Pod、Deployment 这些,而这些资源对象已经有了内置的控制器实现,那么我们还可以如何去使用控制器呢?那就需要去了解 CRD 这种资源对象了。
Custom Resource Define 简称 CRD,是 Kubernetes(v1.7+)为提高可扩展性,让开发者去自定义资源的一种方式。CRD 资源可以动态注册到集群中,注册完毕后,用户可以通过 kubectl 来创建访问这个自定义的资源对象,类似于操作 Pod 一样。不过需要注意的是 CRD 仅仅是资源的定义而已,需要一个对应的控制器去监听 CRD 的各种事件来添加自定义的业务逻辑,这个才是我们要重点学习的。
定义
如果说只是对 CRD 资源本身进行 CRUD 操作的话,不需要 Controller 也是可以实现的,相当于就是只有数据存入了 etcd 中,而没有对这个数据的相关操作而已。比如我们可以定义一个如下所示的 CRD 资源清单文件:
# crd-demo.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# name 必须匹配下面的spec字段:<plural>.<group>
name: crontabs.stable.example.com
spec:
# group 名用于 REST API 中的定义:/apis/<group>/<version>
group: stable.example.com
# 列出自定义资源的所有 API 版本
versions:
- name: v1beta1 # 版本名称,比如 v1、v2beta1 等等
served: true # 是否开启通过 REST APIs 访问 `/apis/<group>/<version>/...`
storage: true # 必须将一个且只有一个版本标记为存储版本
schema: # 定义自定义对象的声明规范
openAPIV3Schema:
description: Define CronTab YAML Spec
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# 定义作用范围:Namespaced(命名空间级别)或者 Cluster(整个集群)
scope: Namespaced
names:
# kind 是 sigular 的一个驼峰形式定义,在资源清单中会使用
kind: CronTab
# plural 名字用于 REST API 中的定义:/apis/<group>/<version>/<plural>
plural: crontabs
# singular 名称用于 CLI 操作或显示的一个别名
singular: crontab
# shortNames 相当于缩写形式
shortNames:
- ct需要注意的是 v1.16 版本以后已经 GA 了,使用的是 v1 版本,之前都是 v1beta1,定义规范有部分变化,所以要注意版本变化。
这个地方的定义和我们定义普通的资源对象比较类似,我们说我们可以随意定义一个自定义的资源对象,但是在创建资源的时候,肯定不是任由我们随意去编写 YAML 文件的,当我们把上面的 CRD 文件提交给 Kubernetes 之后,Kubernetes 会对我们提交的声明文件进行校验,从定义可以看出 CRD 是基于 OpenAPI v3 schem 进行规范的。当然这种校验只是对于字段的类型进行校验,比较初级,如果想要更加复杂的校验,这个时候就需要通过 Kubernetes 的 admission webhook 来实现了。关于校验的更多用法,可以前往官方文档查看。
同样现在我们可以直接使用 kubectl 来创建这个 CRD 资源清单:
$ kubectl apply -f crd-demo.yaml
customresourcedefinition.apiextensions.k8s.io/crontabs.stable.example.com created这个时候我们可以查看到集群中已经有我们定义的这个 CRD 资源对象了:
$ kubectl get crd |grep example
crontabs.stable.example.com 2019-12-19T02:37:54Z这个时候一个新的 namespace 级别的 RESTful API 就会被创建:
/apis/stable/example.com/v1beta1/namespaces/*/crontabs/...然后我们就可以使用这个 API 端点来创建和管理自定义的对象,这些对象的类型就是上面创建的 CRD 对象规范中的 CronTab。
现在在 Kubernetes 集群中我们就多了一种新的资源叫做 crontabs.stable.example.com,我们就可以使用它来定义一个 CronTab 资源对象了,这个自定义资源对象里面可以包含的字段我们在定义的时候通过 schema 进行了规范,比如现在我们来创建一个如下所示的资源清单:
# crd-crontab-demo.yaml
apiVersion: "stable.example.com/v1beta1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image我们可以直接创建这个对象:
$ kubectl apply -f crd-crontab-demo.yaml
crontab.stable.example.com/my-new-cron-object created然后我们就可以用 kubectl 来管理我们这里创建 CronTab 对象了,比如:
$ kubectl get ct # 简写
NAME AGE
my-new-cron-object 42s
$ kubectl get crontab
NAME AGE
my-new-cron-object 88s在使用 kubectl 的时候,资源名称是不区分大小写的,我们可以使用 CRD 中定义的单数或者复数形式以及任何简写。
我们也可以查看创建的这个对象的原始 YAML 数据:
$ kubectl get ct -o yaml
apiVersion: v1
items:
- apiVersion: stable.example.com/v1beta1
kind: CronTab
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"stable.example.com/v1beta1","kind":"CronTab","metadata":{"annotations":{},"name":"my-new-cron-object","namespace":"default"},"spec":{"cronSpec":"* * * * */5","image":"my-awesome-cron-image"}}
creationTimestamp: "2019-12-19T02:52:55Z"
generation: 1
name: my-new-cron-object
namespace: default
resourceVersion: "12342275"
selfLink: /apis/stable.example.com/v1beta1/namespaces/default/crontabs/my-new-cron-object
uid: dace308d-5f54-4232-9c7b-841adf6bab62
spec:
cronSpec: '* * * * */5'
image: my-awesome-cron-image
kind: List
metadata:
resourceVersion: ""
selfLink: ""我们可以看到它包含了上面我们定义的 cronSpec 和 image 字段。
就如上面我们说的,现在我们自定义的资源创建完成了,但是也只是单纯的把资源清单数据存入到了 etcd 中而已,并没有什么其他用处,因为我们没有定义一个对应的控制器来处理相关的业务逻辑,所以接下来我们需要来了解如何为 CRD 创建自定义的控制器。
代码生成器
要实现自己的控制器原理比较简单,前面我们也介绍过如何编写控制器,最重要的就是要去实现 ListAndWatch 操作、获取资源的 Informer 和 Indexer、以及通过一个 workqueue 去接收事件来进行处理,所以我们就要想办法来编写我们自定义的 CRD 资源对应的 Informer、ClientSet 这些工具,前面我们已经了解了对于内置的 Kubernetes 资源对象这些都是已经内置到源码中了,对于我们自己的 CRD 资源肯定不会内置到源码中的,所以就需要我们自己去实现,比如要为 CronTab 这个资源对象实现一个 DeepCopyObject 函数,这样才会将我们自定义的对象转换成 runtime.Object,系统才能够识别,但是客户端相关的操作实现又非常多,而且实现方式基本上都是一致的,所以 Kubernetes 就为我们提供了代码生成器这样的工具,我们可以来自动生成客户端访问的一些代码,比如 Informer、ClientSet 等等。
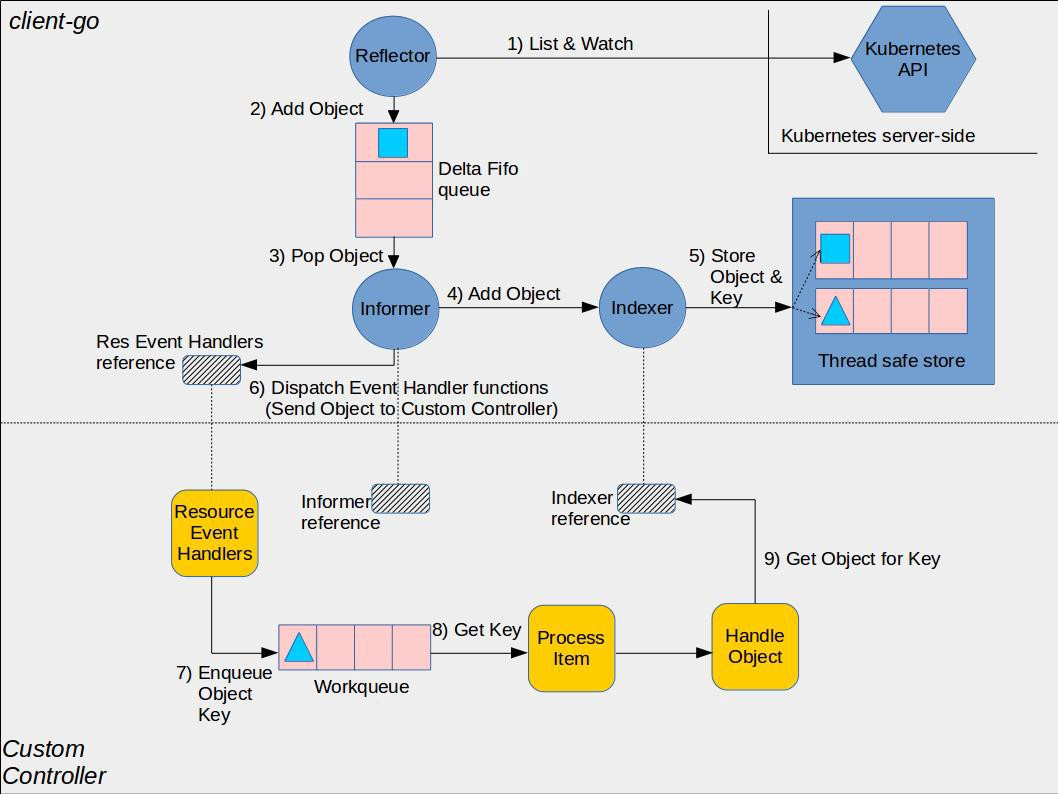
code-generator
code-generator 就是 Kubernetes 提供的一个用于代码生成的项目,它提供了以下工具为 Kubernetes 中的资源生成代码:
deepcopy-gen: 生成深度拷贝方法,为每个 T 类型生成func (t* T) DeepCopy() *T方法,API 类型都需要实现深拷贝client-gen: 为资源生成标准的 clientsetinformer-gen: 生成 informer,提供事件机制来响应资源的事件lister-gen: 生成Lister**,**为 get 和 list 请求提供只读缓存层(通过 indexer 获取)
Informer 和 Lister 是构建控制器的基础,使用这4个代码生成器可以创建全功能的、和 Kubernetes 上游控制器工作机制相同的 production-ready 的控制器。
code-generator 还包含一些其它的代码生成器,例如 Conversion-gen 负责产生内外部类型的转换函数、Defaulter-gen 负责处理字段默认值。大部分的生成器支持–input-dirs参数来读取一系列输入包,处理其中的每个类型,然后生成代码:
部分代码生成到输入包所在目录,例如 deepcopy-gen 生成器,也可以使用参数--output-file-base "zz_generated.deepcopy" 来定义输出文件名
其它代码生成到 --output-package 指定的目录,例如 client-gen、informer-gen、lister-gen 等生成器
在开发 CRD 的控制器的时候,我们可以编写一个脚本来统一调用生成器生成代码,我们可以直接使用 sample-controller 仓库中提供的 hack/update-codegen.sh 脚本。
#!/usr/bin/env bash
set -o errexit
set -o nounset
set -o pipefail
SCRIPT_ROOT=$(dirname "${BASH_SOURCE[0]}")/..
# 代码生成器包的位置
CODEGEN_PKG=${CODEGEN_PKG:-$(cd "${SCRIPT_ROOT}"; ls -d -1 ./vendor/k8s.io/code-generator 2>/dev/null || echo ../code-generator)}
# generate-groups.sh <generators> <output-package> <apis-package> <groups-versions>
# 使用哪些生成器,可选值 deepcopy,defaulter,client,lister,informer,逗号分隔,all表示全部使用
# 输出包的导入路径
# CR 定义所在路径
# API 组和版本
bash "${CODEGEN_PKG}"/generate-groups.sh "deepcopy,client,informer,lister" \
k8s.io/sample-controller/pkg/generated k8s.io/sample-controller/pkg/apis \
samplecontroller:v1alpha1 \
--output-base "$(dirname "${BASH_SOURCE[0]}")/../../.." \
--go-header-file "${SCRIPT_ROOT}"/hack/boilerplate.go.txt
# 自动生成的源码头部附加的内容:
# --go-header-file "${SCRIPT_ROOT}"/hack/custom-boilerplate.go.txt执行上面的脚本后,所有 API 代码会生成在 pkg/apis 目录下,clientsets、informers、listers 则生成在 pkg/generated 目录下。不过从脚本可以看出需要将 code-generator 的包放置到 vendor 目录下面,现在我们都是使用 go modules 来管理依赖包,我们可以通过执行 go mod vendor 命令将依赖包放置到 vendor 目录下面来。
我们还可以进一步提供 hack/verify-codegen.sh 脚本,用于判断生成的代码是否 up-to-date:
#!/usr/bin/env bash
set -o errexit
set -o nounset
set -o pipefail
# 先调用 update-codegen.sh 生成一份新代码
# 然后对比新老代码是否一样
SCRIPT_ROOT=$(dirname "${BASH_SOURCE[0]}")/..
DIFFROOT="${SCRIPT_ROOT}/pkg"
TMP_DIFFROOT="${SCRIPT_ROOT}/_tmp/pkg"
_tmp="${SCRIPT_ROOT}/_tmp"
cleanup() {
rm -rf "${_tmp}"
}
trap "cleanup" EXIT SIGINT
cleanup
mkdir -p "${TMP_DIFFROOT}"
cp -a "${DIFFROOT}"/* "${TMP_DIFFROOT}"
"${SCRIPT_ROOT}/hack/update-codegen.sh"
echo "diffing ${DIFFROOT} against freshly generated codegen"
ret=0
diff -Naupr "${DIFFROOT}" "${TMP_DIFFROOT}" || ret=$?
cp -a "${TMP_DIFFROOT}"/* "${DIFFROOT}"
if [[ $ret -eq 0 ]]
then
echo "${DIFFROOT} up to date."
else
echo "${DIFFROOT} is out of date. Please run hack/update-codegen.sh"
exit 1
fi代码生成 tag
除了通过命令行标记控制代码生成器之外,我们一般是在源码中使用 tag 来标记一些供生成器使用的属性,这些tag主要分为两类:
在 doc.go 的 package 语句之上提供的全局 tag
在需要被处理的类型上提供的局部 tag
tag 的使用方法如下所示:
// +tag-name
// 或者
// +tag-name=value我们可以看到 tag 是通过注释的形式存在的,另外需要注意的是 tag 的位置非常重要,很多 tag 必须直接位于 type 或 package 语句的上一行,另外一些则必须和 go 语句隔开至少一行空白。
全局 tag
必须在目标包的 doc.go 文件中声明,一般路径为 pkg/apis/<apigroup>/<version>/doc.go如下所示:
// 为包中任何类型生成深拷贝方法,可以在局部 tag 覆盖此默认行为
// +k8s:deepcopy-gen=package
// groupName 指定 API 组的全限定名
// 此 API 组的 v1 版本,放在同一个包中
// +groupName=example.com
package v1注意: 空行不能省
局部 tag
要么直接声明在类型之前,要么位于类型之前的第二个注释块中。下面的 types.go 中声明了 CR 对应的类型:
// 为当前类型生成客户端,如果不加此注解则无法生成 lister、informer 等包
// +genclient
// 提示此类型不基于 /status 子资源来实现 spec-status 分离,产生的客户端不具有 UpdateStatus 方法
// 否则,只要类型具有 Status 字段,就会生成 UpdateStatus 方法
// +genclient:noStatus
// 为每个顶级 API 类型添加,自动生成 DeepCopy 相关代码
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// K8S 资源,数据库
type Database struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec DatabaseSpec `json:"spec"`
}
// 不为此类型生成深拷贝方法
// +k8s:deepcopy-gen=false
// 数据库的规范
type DatabaseSpec struct {
User string `json:"user"`
Password string `json:"password"`
Encoding string `json:"encoding,omitempty"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// 数据库列表,因为 list 获取的是列表,所以需要定义该结构
type DatabaseList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata"`
Items []Database `json:"items"`
}在上面 CR 的定义上面就通过 tag 来添加了自动生成相关代码的一些注释。此外对于集群级别的资源,我们还需要提供如下所示的注释:
// +genclient:nonNamespaced
// 下面的 Tag 不能少
// +genclient另外我们还可以控制客户端提供哪些 HTTP 方法:
// +genclient:noVerbs
// +genclient:onlyVerbs=create,delete
// +genclient:skipVerbs=get,list,create,update,patch,delete,deleteCollection,watch
// 仅仅返回 Status 而非整个资源
// +genclient:method=Create,verb=create,result=k8s.io/apimachinery/pkg/apis/meta/v1.Status
// 下面的 Tag 不能少
// +genclient使用 tag 定义完需要生成的代码规则后,执行上面提供的代码生成脚本即可自动生成对应的代码了



 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系