
前言
与仅限于使用GPT系列模型的Assistant API框架不同,LangGraph是一个适用范围更广的AI Agent开发框架。在大模型的支持方面,LangGraph不仅支持GPT系列,还兼容其他多种在线或开源模型,例如 glm4、llama3和Qwen等,可以说热门的大模型均可以接入到该框架中进行AI Agent应用程序的开发。而关于大模型的接入方式,我们既可以通过传统的openai api等原生方式将大模型集成到LangGraph构建的AI Agent流程中,也可以利用ollma、vllm等大模型推理加速库,实现更加便捷和高效的集成。除此之外,在AI Agent的构建范式上,LangGraph不仅提供了预配置的ReAct代理机制,还支持更多自定义的如Planning策略的接入,以满足不同应用场景的需求。
从这三大方面来看,LangGraph的高度自主性和开放性确实让它在功能和灵活性上相较于Assistant API具有明显的优势。但需要注意的是,这种自主性和可扩展性也带来了更高的复杂性和开发要求。使用LangGraph意味着开发者需要进行较多的自主开发工作。此外,LangGraph框架的底层架构复杂非常复杂,这直接导致了LangGraph的学习和使用门槛相对较高。并且,经过我们长时间的探索和实践会明显发现,即使是经过多轮的尝试和优化,使用LangGraph构建的AI Agent应用程序的效果也很难超过用Assistant API几行代码就能实现的效果。所以,我们要想掌握和应用LangGraph,势必要投入更多的时间和精力。
从名字上看,应该是和Langchain有着非常紧密的关系,而事实也确实是这样。因为LangGraph 就是以 LangChain 表达式语言为基础而构建起来的用于开发AI Agent的一个框架。所以我们上面提到的关于LangGragh在大模型的支持、接入和AI Agent构建方面的优势,都可以非常自然的从LangChain中迁移过来。从大模型技术发展的角度来看,大模型本身是无法采取任何行动的,它们的作用只是用来输出文本,即接收用户的输入并对这些输入给出响应。为了更好和更高效的做到这件事情,langchain项目在2023年就建立起了非常活跃的社区来定义大模型的应用规范。发展到现在,LangChain现在也发布了3个大的版本,而在其整个的构建体系中,一个重要用例是创建代理。在LangChain中,构建AI Agent的底层架构如下图所示:👇
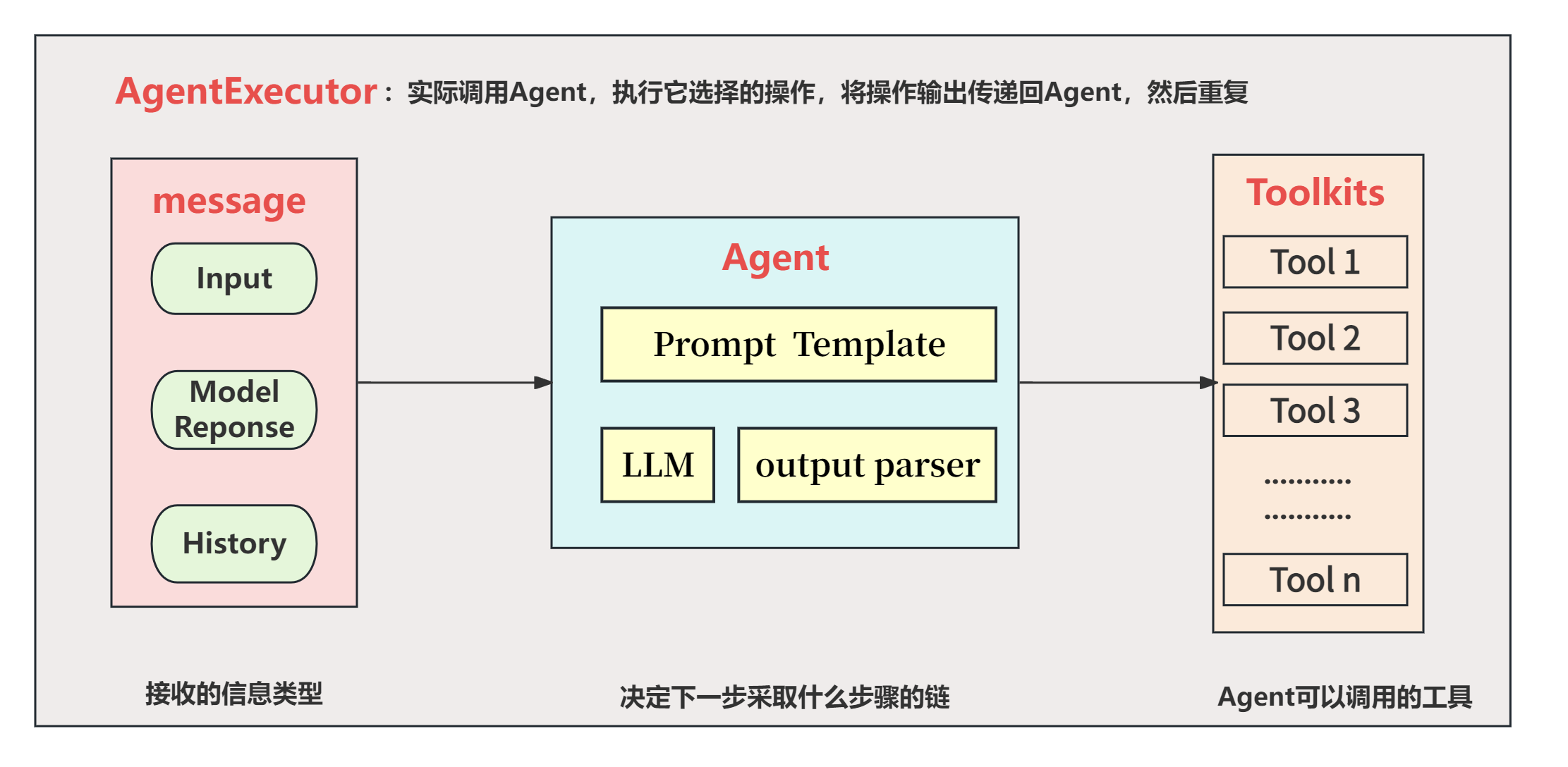
首先,langChain框架中的AI Agent设计,在内部结构会将其分为三个核心的组件,分别是Agent,Message和Toolkits。每个Agent组件一般会由大语言模型 + 提示 + 输出解析器构成,形成一个Chain去处理用户的输入。而Agent能够处理的输入主要来源于三个方面:input代表用户的原始输入,Model Response指的是模型对某一个子任务的响应输出,而History则能携带上下文的信息。其输出部分,则链接到实际的工具库,需要调用哪些工具,将由经过Agent模块后拆分的子任务来决定。大模型调用外部函数会分为两个过程:识别工具和实际执行。在Message -> Agent -> Toolkits 这个流程中,负责的是将子任务拆解,然后根据这些子任务在工具库中找到相应的工具,提取工具名称及所需参数,这个过程可以视作一种“静态”的执行流程。而将这些决策转化为实际行动的工作,则会交给AgentExecutor。
所以综上需要理解的是:在LangChain的AI Agent实际架构中,Agent的角色是接收输入并决定采取的操作,但它本身并不直接执行这些操作。这一任务是由AgentExecutor来完成的。将Agent(决策大脑)与AgentExecutor(执行操作的Runtime)结合使用,才构成了完整的Agents(智能体),其中AgentExecutor负责调用代理并执行指定的工具,以此来实现整个智能体的功能。
LangGraph底层原理介绍
LangChain发展至现在,仍然是构建大语言模型应用程序的前沿框架之一。特别是在最新发布的v0.3版本中,已经基本完成了由传统类到表达式语言(LCEL)的重要过渡,给开发者带来的直接利好就是定义和执行分步操作序列(也称为链)会更加简单。用更专业的术语来说,使用LangChain 构建的是 DAG(有向无环图)。而之所以会出现LangGraph框架,根本原因是在于随着AI应用(特别是AI Agent)的发展,对于大语言模型的使用不仅仅是作为执行工具,而更多作为推理引擎的需求在日益增长。这种转变带来的是更多的重复(循环)和复杂条件的交互需求,这就导致基于LCEL的线性序列构建方式在构建更复杂、更智能的系统时显示出了明显的局限性。如下所示的代码就是在LangChain中通过LECL表达式语言构建Chain的一种最简单的方式:
LangChain ChatOpenAI:https://python.langchain.com/docs/integrations/chat/openai/
import getpass
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
llm = ChatOpenAI(model="gpt-4o")
prompt = ChatPromptTemplate.from_messages(
[
("system","You are a helpful assistant that translates {input_language} to {output_language}."),
("human", "{input}"),
]
)
chain = prompt | llm
chain.invoke(
{
"input_language": "English",
"output_language": "Chinese",
"input": "I love programming.",
}
)反观LangGraph,顾名思义,LangGraph 在图这个概念上有很大的侧重,它的出现就是要解决线性序列的局限性问题,而解决的方法就是循环图。在LangGraph框架中,用图取代了LangChain的AgentExecutor(代理执行器),用来管理代理的生命周期并在其状态内将暂存器作为消息进行跟踪,增加了以循环方式跨各种计算步骤协调多个链或参与者的功能。这就与 LangChain 将代理视为可以附加工具和插入某些提示的对象不同,对于图来说,意味着我们可以从任何可运行的功能或代理或链作为一个程序的起点。
上面过于专业描述可能理解起来比较困难,所以这里我们通过一个简单直观的场景来详细解释。
在以图构建的框架中,任何可执行的功能都可以作为对话、代理或程序的启动点。这个启动点可以是大模型的 API 接口、基于大模型构建的 AI Agent,通过 LangChain 或其他技术建立的线性序列等等,即下图中的 "Start" 圆圈所示。无论哪种形式,它都首先处理用户的输入,并决定接下来要做什么。下图展示了在 LangGraph 概念下,最基本的一种代理模型:👇
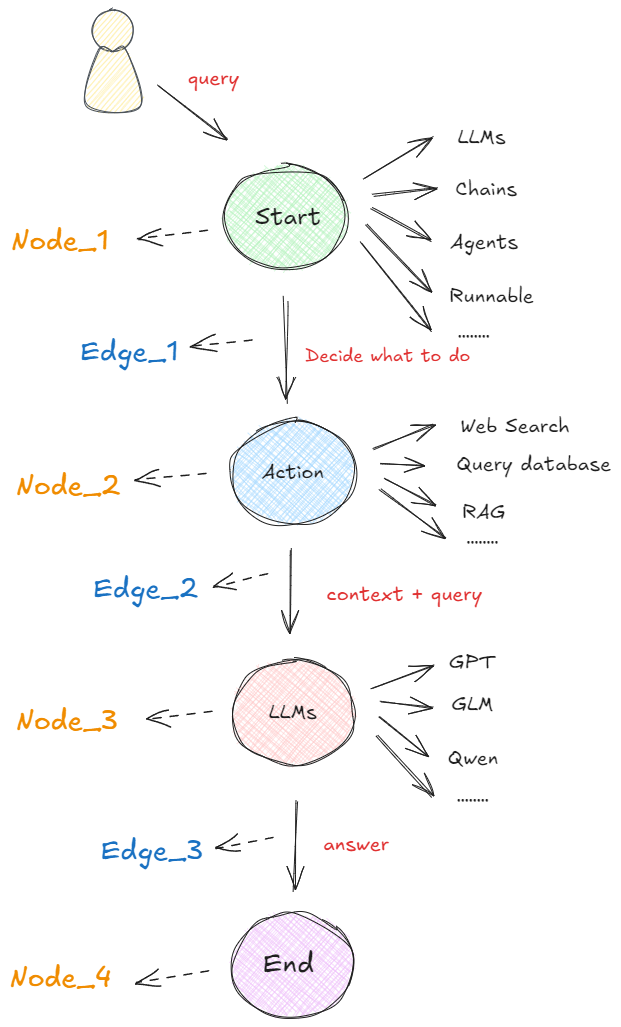
在启动点定义的可运行功能会根据收到的输入决定是否进行检索以及如何响应。比如在执行过程中,如果需要检索信息,则可以利用搜索工具来实现,比如Web Search(网络搜索)、Query Database(查询数据库)、RAG等获取必要的信息(图中的 "Action" 圆圈)。接下来,再使用一个大语言模型(LLM)处理工具提供的信息,结合用户最初传入的初始查询,生成最终的响应(图中的 "LLMs" 圆圈)。最终,这个响应被传递至终点节点(图中的 "End" 圆圈)。
上图所示的流程就是在LangGraph概念中一个非常简单的代理构成形式。关键且必须清楚的概念是:在这里,每个圆圈代表一个“节点”(Nodes),每个箭头表示一条“边”(Edges)。因此,在 LangGraph 中,无论代理的构建是简单还是复杂,它最终都是由节点和边通过特定的组合形成的图。这样的构建形式形成的工作流原理就是:当每个节点完成工作后,通过边告诉下一步该做什么,所以也就得出了:LangGraph的底层图算法就是在使用消息传递来定义通用程序。当节点完成其操作时,它会沿着一条或多条边向其他节点发送消息。然后,这些接收节点执行其功能,将结果消息传递给下一组节点,然后该过程继续。如此循环往复。
这就是LangGraph底层架构设计中图算法的根本思想。
LangGraph底层源码解析
Graph基类
对于任意一个简单或者复杂的图来说,都是基于Graph类来构建和管理图结构的。在Graph类中允许添加节点、边,并定义节点间的动态流转逻辑。如下是Graph类的主要组成部分和功能:
python
from collections import defaultdict
from typing import Any, Callable, Dict, Optional, Set, Tuple, Union, Awaitable, Hashable
class Graph:
def __init__(self) -> None:
self.nodes: Dict[str, Any] = {} # 一个字典,用于存储图中的所有节点。每个节点可以是一个字符串标识或者是一个可调用对象
self.edges: Set[Tuple[str, str]] = set() # 一个集合,用来存储图中所有的边,边由一对节点名称组成,表示从一个节点到另一个节点的直接连接。
self.branches: defaultdict = defaultdict(dict) # 一个默认字典,用于存储条件分支,允许从一个节点根据特定条件转移到多个不同的节点。
self.support_multiple_edges = False # 一个布尔值,指示图是否支持同一对节点间的多条边。
self.compiled = False # 一个布尔值,表示图是否已经被编译。编译是指图的结构已经设置完毕,准备进行执行。
您暂时无权查看此隐藏内容!
def compile(self, checkpointer=None, interrupt_before: Optional[Set[str]] = None, interrupt_after: Optional[Set[str]] = None, debug: bool = False) -> 'Graph':
"""
编译图,确认图的结构合法且可执行后,准备图以供执行。
"""
pass从源码中可以看出,Graph该类提供了丰富的方法来控制图的编译和执行,使其适用于需要复杂逻辑和流程控制的应用场景。
GraphState
定义图时要做的第一件事是定义图的State。状态表示会随着图计算的进行而维护和更新的上下文或记忆。它用来确保图中的每个步骤都可以访问先前步骤的相关信息,从而可以根据整个过程中积累的数据进行动态决策。这个过程通过状态图StateGraph类实现,它继承自 Graph 类,这意味着 StateGraph 会使用或扩展基类的属性和方法。
python
from collections import defaultdict
from typing import Any, Callable, Dict, Optional, Set, Tuple, Type, Union
class StateGraph(Graph):
"""StateGraph 是一个管理状态并通过定义的输入和输出架构支持状态转换的图。"""
def __init__(self, state_schema: Optional[Type[Any]] = None, config_schema: Optional[Type[Any]] = None) -> None:
super().__init__()
self.state_schema = state_schema # 一个可选的类型参数,定义图状态的结构。这是用于定义和验证图中节点处理的状态数据的模式。
self.config_schema = config_schema # 一个可选的类型参数,用于定义配置的结构。这可以用于定义和验证图的配置参数。
self.nodes: Dict[str, Any] = {} # 一个字典,用于存储图中的节点。每个节点可以关联特定的动作和其他数据。
self.edges: Set[Tuple[str, str]] = set() # 一个集合,存储图中所有的边。每条边由一对字符串组成,表示从一个节点到另一个节点的连接。
self.branches: defaultdict = defaultdict(dict) # 一个默认字典,用于管理节点间的条件分支。这使得从一个节点基于某些条件跳转到不同的节点成为可能。
def add_node(self, node: Union[str, Callable], action: Optional[Callable] = None, *, metadata: Optional[Dict[str, Any]] = None) -> 'StateGraph':
"""向图中添加一个新节点。节点可以是一个具名字符串或一个可调用对象(如函数), 如果node是字符串,则action应为与节点关联的可调用动作。"""
pass
def add_edge(self, start_key: str, end_key: str) -> 'StateGraph':
"""在图中添加一条边,连接两个节点。"""
pass
def compile(self) -> 'CompiledStateGraph':
"""编译图,将其转换成可运行的形式。包括验证图的完整性、预处理数据等。"""
pass
什么是图的模式
默认情况下,StateGraph使用单模式运行,这意味着在图中的任意阶段都会读取和写入相同的状态通道,所有节点都使用该状态通道进行通信。除此之外,在某些情况下如果希望对图的状态有更多的控制,比如:
- 内部节点可以传递图的输入/输出中不需要的信息。
- 对图使用不同的输入/输出模式。例如,输出可能仅包含单个相关输出键。
LangGraph的底层实现上提供了多种不同图模式的支持,这可以通过state_schema来进行灵活的指定。
首先来看图的单模式。任何模式都包含输入和输出,输入模式需要确保提供的输入与预期结构匹配,而输出模式根据定义的输出模式过滤内部数据以仅返回相关信息。而这个预期结构的校验,由TypedDict工具来限定。
TypeDict
TypedDict 是 Python 类型注解系统中的一个工具,它允许为字典中的键指定期望的具体类型。在 Python 的 typing 模块中定义,通常用于增强代码的可读性和安全性,特别是在字典对象结构固定且明确时。示例代码如下:
from typing import TypedDict
class Contact(TypedDict):
name: str
email: str
phone: str
def send_email(contact: Contact) -> None:
print(f"Sending email to {contact['name']} at {contact['email']}")
# 使用定义好的 TypedDict 创建字典
contact_info: Contact = {
'name': 'Alice',
'email': 'alice@example.com',
'phone': '123-456-7890'
}
send_email(contact_info)在这个示例中,Contact 类型定义了三个必须的字段:name,email,和 phone,每个字段都是字符串(Str)形式。当创建 contact_info 字典时,必须提供所有这些字段。函数 send_email 则利用这个类型安全的字典进行操作。这样的 TypedDict 使用场景非常适合那些需要确保字典中具有特定字段和类型的应用场景,如处理从外部API返回的数据或者在内部各个模块间传递复杂的数据结构,因为在LangGraph图中,每个节点传递到下一个节点的数据,将直接影响到下一个节点能否顺利执行。
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
# 定义输入的模式
class InputState(TypedDict):
question: str
# 定义输出的模式
class OutputState(TypedDict):
answer: str
# 将 InputState 和 OutputState 这两个 TypedDict 类型合并成一个字典类型。
class OverallState(InputState, OutputState):
pass接下来,创建一个 StateGraph 对象,使用 OverallState 作为其状态定义,同时指定了输入和输出类型分别为 InputState 和 OutputState,代码如下:
builder = StateGraph(OverallState, input=InputState, output=OutputState)创建 builder 对象后,相当于构建了一个图结构的框架。接下来的步骤是向这个图中添加节点和边,完善和丰富图的内部执行逻辑。
Nodes
在 LangGraph 中,节点是一个 python 函数(sync 或async ),接收当前State作为输入,执行自定义的计算,并返回更新的State。所以其中第一个位置参数是state 。
def agent_node(state:InputState):
print("我是一个AI Agent。")
return 定义好了节点以后,我们需要使用add_node方法将这些节点添加到图中。在将节点添加到图中的时候,可以自定义节点的名称。而如果不指定名称,则会为自动指定一个与函数名称等效的默认名称。代码如下:
builder.add_node("agent_node", agent_node)现在有了图结构,并且图结构中也存在孤立的节点agent_node,接下来我们要做的事就是需要将图中的节点按照我们所期望的方式进行连接,这需要用到的就是Edges – 边。
Edges
Edges(边)用来定义逻辑如何路由以及图何时开始与停止。这是代理工作以及不同节点如何相互通信的重要组成部分。有几种关键的边类型:
- 普通边:直接从一个节点到下一个节点。
- 条件边:调用函数来确定下一个要转到的节点。
- 入口点:当用户输入到达时首先调用哪个节点。
- 条件入口点:调用函数来确定当用户输入到达时首先调用哪个节点。
先看普通边。如果直接想从节点A到节点B,可以直接使用add_edge方法。注意:LangGraph有两个特殊的节点:START和END。START表示将用户输入发送到图的节点。使用该节点的主要目的是确定应该首先调用哪些节点。END节点是代表终端节点的特殊节点。当想要指示哪些边完成后没有任何操作时,将使用该节点。因此,一个完整的图就可以使用如下代码进行定义:
from langgraph.graph import START, END
builder.add_edge(START, "agent_node")
builder.add_edge("action_node", END)最后,通过compile编译图。在编译过程中,会对图结构执行一些基本检查(如有没有孤立节点等)。代码如下:
graph = builder.compile()至此,我们已经成功构建了一个完整的图结构,并准备好接收用户的请求。
Graph 的调用方法
要调用图中的方法,可以使用 invoke 方法。示例代码如下:
graph.invoke({"question":"你好"})在这个过程中,我们将state: InputState作为输入模式传递给agent_node,在传递到action_node,最后由action_node传递到END节点。节点之间通过边是已经构建了完整的通路,那么如果我们想要传递每个节点的状态信息,则可以稍加修改即可实现。对于图模式,我们的定义方法如下:
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
from langgraph.graph import START, END
您暂时无权查看此隐藏内容!
# 添加节点
builder.add_node("agent_node", agent_node)
builder.add_node("action_node", action_node)
# 添加便
builder.add_edge(START, "agent_node")
builder.add_edge("agent_node", "action_node")
builder.add_edge("action_node", END)
# 编译图
graph = builder.compile()
graph.invoke({"question":"今天的天气怎么样?"})输出

不同节点间能够传递信息的原因是因为节点可以写入图状态中的任何状态通道。图状态是初始化时定义的状态通道的并集,而我们定义的状态通道包含了OverallState以及过滤器InputState和OutputState 。
使用LangGraph构建大模型的问答流程
import getpass
import os
from langgraph.graph import StateGraph
from typing_extensions import TypedDict
from langgraph.graph import START, END
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv
load_dotenv()
MODEL_NAME="deepseek-chat"
BASE_URL="https://api.deepseek.com/v1"
您暂时无权查看此隐藏内容!
# 添加节点
builder.add_node("llm_node", llm_node)
builder.add_node("action_node", action_node)
# 添加便
builder.add_edge(START, "llm_node")
builder.add_edge("llm_node", "action_node")
builder.add_edge("action_node", END)
# 编译图
graph = builder.compile()
final_answer = graph.invoke({"question":"你好,请你详细的介绍一下你自己"})
print(final_answer["answer"])当深入理解了LangGraph的底层原理及其图结构构建的逻辑后,我们是可以明显感受到其相较于LangChain中的AI Agent架构,展现出了更高的灵活性和扩展性。在LangGraph中,我们可以在各个Python函数中定义节点的核心逻辑,并通过边来确定输入与输出模式。此外,节点函数在定义时还可以自主构建中间状态的信息。尽管在本示例中我们使用LangChain来接入大模型,但通过节点函数的定义逻辑来看,我们当然也可以完全不依赖LangChain,而采用原生方法进行接入。




 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系





