
代理架构的演进:为什么需要 Router?
在 LangGraph 构建的 AI Agent 生态中,代理架构的核心使命是赋予大模型「控制权」—— 从基础的路径选择到复杂的任务闭环,控制权的精细化程度决定了系统解决问题的边界。当我们期望输入一个需求即可获得完整结果时,背后需要一套能够动态调度、条件分支的逻辑引擎,而 Router(路由代理)正是这一引擎的核心组件。
代理架构分类与 Router 的定位
LangGraph 将代理架构抽象为四大类:
- Router Agent(路由代理):基于条件判断实现逻辑分流,解决「在多个路径中选哪条」的问题。
- 工具代理:调用外部工具完成特定任务(如数据库查询、API 调用)。
- 自主循环代理:支持多轮工具调用与结果评估,直至满足终止条件。
- 多代理:协调多个独立代理协作完成复杂任务。
Router 是一切复杂代理的基础:即使是自主循环或多代理场景,其内部也往往依赖 Router 实现分支控制。例如,工具代理在调用前可能需要通过 Router 判断是否需要调用工具,或选择调用哪个工具。
Router 的核心机制:条件边与逻辑分流
在 LangGraph 中,Router 的能力通过 「条件边(Conditional Edge)」 实现 —— 这是一种带判断逻辑的图边,允许大模型根据运行时状态(如输入数据、中间结果)动态选择下一个节点。其核心实现包含两大要素:
- 条件边的编程接口:add_conditional_edges
通过该方法可定义从源节点出发的条件分支,核心参数包括:
source:起始节点名称
path:路由函数,接收当前状态 state,返回目标节点名或映射键
path_map(可选):将路由函数的返回值映射到目标节点(解耦逻辑判断与节点名称)
then(可选):目标节点执行后的后续节点
基础用法:直接返回节点名
from langgraph.graph import StateGraph, START, END
def node_a(state): return {"x": state["x"] + 1}
def node_b(state): return {"x": state["x"] - 2}
def node_c(state): return {"x": state["x"] * 3}
builder = StateGraph(dict)
builder.add_nodes_from([("node_a", node_a), ("node_b", node_b), ("node_c", node_c)])
# 定义路由函数:根据 state.x 的值选择下一个节点
def routing_func(state):
if state["x"] > 10:
return "node_b" # 直接返回节点名
else:
return "node_c"
builder.add_conditional_edges(START, routing_func) # 从起始节点开始路由
builder.add_edge("node_b", END)
builder.add_edge("node_c", END)进阶用法:通过 path_map 解耦逻辑与节点
def simplified_routing(state):
return state["x"] > 10 # 返回布尔值作为映射键
builder.add_conditional_edges(
source=START,
path=simplified_routing,
path_map={True: "node_b", False: "node_c"} # 映射键到节点名
)- 可视化与调试:Mermaid 图的生成
通过graph.get_graph(xray=True).draw_mermaid_png()可生成带路由逻辑的流程图,例如:
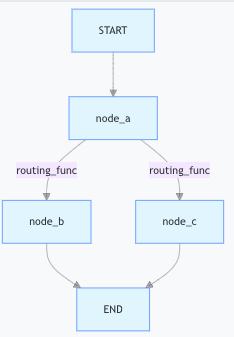
该功能极大简化了复杂路由逻辑的调试,开发者可直观看到不同条件下的路径走向。
真实场景落地:Router 在多模态输入处理中的应用
场景描述:构建智能客服 Agent
需求:客服系统需根据用户输入类型(查询、问候、投诉)路由到不同处理流程:
- 结构化查询(如「查询订单号 12345」)→ 调用数据库查询节点
- 自然语言问候(如「你好」)→ 直接返回问候语节点
- 投诉内容 → 路由到人工处理节点
实现步骤:
- 定义路由函数:解析输入类型
def input_classifier(state): query = state["input"] if re.match(r"查询\s+", query): return "db_query" elif query.lower() in ["你好", "hi"]: return "greeting" elif re.search(r"投诉|差评", query): return "human_escalation" else: return "unknown" - 构建状态图与条件边
builder = StateGraph(dict)
builder.add_nodes_from([
("db_query", db_query_node),
("greeting", greeting_node),
("human_escalation", human_escalation_node),
("unknown", unknown_node)
])
builder.add_conditional_edges(
source=START,
path=input_classifier,
path_map={
"db_query": "db_query",
"greeting": "greeting",
"human_escalation": "human_escalation",
"unknown": "unknown"
}
)
builder.add_edge("db_query", END)
builder.add_edge("greeting", END)
builder.add_edge("human_escalation", END)
builder.add_edge("unknown", END)- 结合大模型结构化输出
在实际应用中,用户输入可能是非结构化的(如自由文本),需通过大模型先提取关键信息。此时可结合 LangGraph 的 三种结构化输出能力:
(1)提示工程:直接引导大模型输出格式
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o-mini")
prompt = ChatPromptTemplate.from_messages([
("system", "Answer the user query. Wrap the output in `json`"),
("human", "{query}")
])
chain = prompt | llm
# 示例输出:`json{"type":"查询","content":"订单号12345"}`(2)提示工程 + 输出解析器:后处理格式化
from langchain_core.messages import AIMessage
import re, json
def extract_json(message: AIMessage):
pattern = r"\`\`\`json(.*?)\`\`\`"
matches = re.findall(pattern, message.content, re.DOTALL)
return [json.loads(match.strip()) for match in matches]
chain = prompt | llm | extract_json
# 解析后输出:[{"type":"查询","content":"订单号12345"}](3)内置工具:.with_structured_output()(推荐)
from pydantic import BaseModel
from langgraph.llms import OpenAI
# 定义输出模型
class InputType(BaseModel):
type: str # 查询/问候/投诉
content: str
llm = OpenAI().with_structured_output(InputType)
result = llm.invoke({"input": "查询订单号12345"})
# 直接输出 Pydantic 对象:InputType(type="查询", content="订单号12345")关键结论:
提示工程简单但不稳定(大模型可能不遵守格式)。
输出解析器通过后处理提升可靠性,但增加代码复杂度。
.with_structured_output() 结合 Pydantic/JSON Schema,实现类型安全的结构化输出,是 LangGraph 推荐的最佳实践。
Router 与大模型的交互本质:结构化输出驱动逻辑分流
在 LangGraph 中,Router 的决策依据是大模型生成的结构化数据,这一过程可拆解为:
大模型处理输入:通过提示词或工具调用,将非结构化输入(如自然语言)转换为结构化标签(如 {"type": "查询"})。
Router 执行分流:根据结构化标签中的键值(如 type 字段),匹配 path_map 中的目标节点。
示例流程:

核心优势:
将「语义理解」交给大模型,「逻辑控制」交给 Router,实现专业分工。
结构化输出为 Router 提供了明确的决策依据,避免大模型直接参与流程控制的不可控性。
最佳实践:如何设计高效的路由逻辑?
- 分层路由策略
第一层:粗粒度分类(如输入类型:文本 / 图片 / 语音)
第二层:细粒度处理(如文本类型:查询 / 命令 / 反馈)
优势:降低单个路由函数的复杂度,提升可维护性 - 动态参数传递
在路由函数中可访问全局状态 state,实现基于历史数据的决策:
def session_based_routing(state):
# 根据历史对话次数决定是否转人工
if state["session_count"] > 5 and not state["resolved"]:
return "human_escalation"
else:
return "auto_respond"- 错误处理与默认路径
始终为路由设置默认分支(如 unknown 节点),避免因条件不匹配导致流程中断:builder.add_conditional_edges( source=START, path=input_classifier, path_map=..., default="unknown" # 新增默认路径参数(LangGraph 扩展用法示例) )
延伸思考:Router 的边界与未来扩展
- 适用场景:适合条件明确、可枚举的逻辑分流(如规则引擎、工单分类)。
- 不适用场景:需模糊决策或多轮推理的场景(如复杂业务审批),此时需结合自主循环代理。
- 未来方向:支持概率路由(如根据置信度选择多条路径)、实时参数调优(如根据流量动态调整路由权重)。
结语
Router 是 LangGraph 中「让大模型听话」的关键组件,通过「结构化输出 + 条件边」的组合,它将大模型的创造力与系统的可控性完美结合。本文不仅覆盖了 Router 的基础用法与代码示例,更深入探讨了其与大模型的交互机制、结构化输出的最佳实践,这些都是构建健壮 AI Agent 的核心能力。下一篇我们将围绕「结构化输出」「工具代理」展开,探索如何通过 Router 实现更复杂的工具调用链路。




 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系


