简介
一、Prometheus 是什么?
Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。SoundCloud是搞云计算的一家国外的公司,也是由一位工程师来到这家公司之后开发的这个系统,自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会
(CNCF),成为继Kubernetes之后的第二个项目,这个项目发展的还是比较快的,随着k8s的发展,它也起来了。
https://prometheus.io 官方网站
https://github.com/prometheus GitHub地址
系统组成部份
- Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
- ClientLibrary:客户端库,这些可以集成一些很多的语言中,比如使用JAVA开发的一个Web网站,那么可以集成JAVA的客户端,去暴露相关的指标,暴露自身的指标,但很多的业务指标需要开发去写的,
- Push Gateway:短期存储指标数据。主要用于临时性的任务
- Exporters:采集已有的第三方服务监控指标并暴露metrics,相当于一个采集端的agent,
- Alertmanager:告警
- Web UI:简单的Web控制台
该图说明了Prometheus的体系结构及其某些生态系统组件:
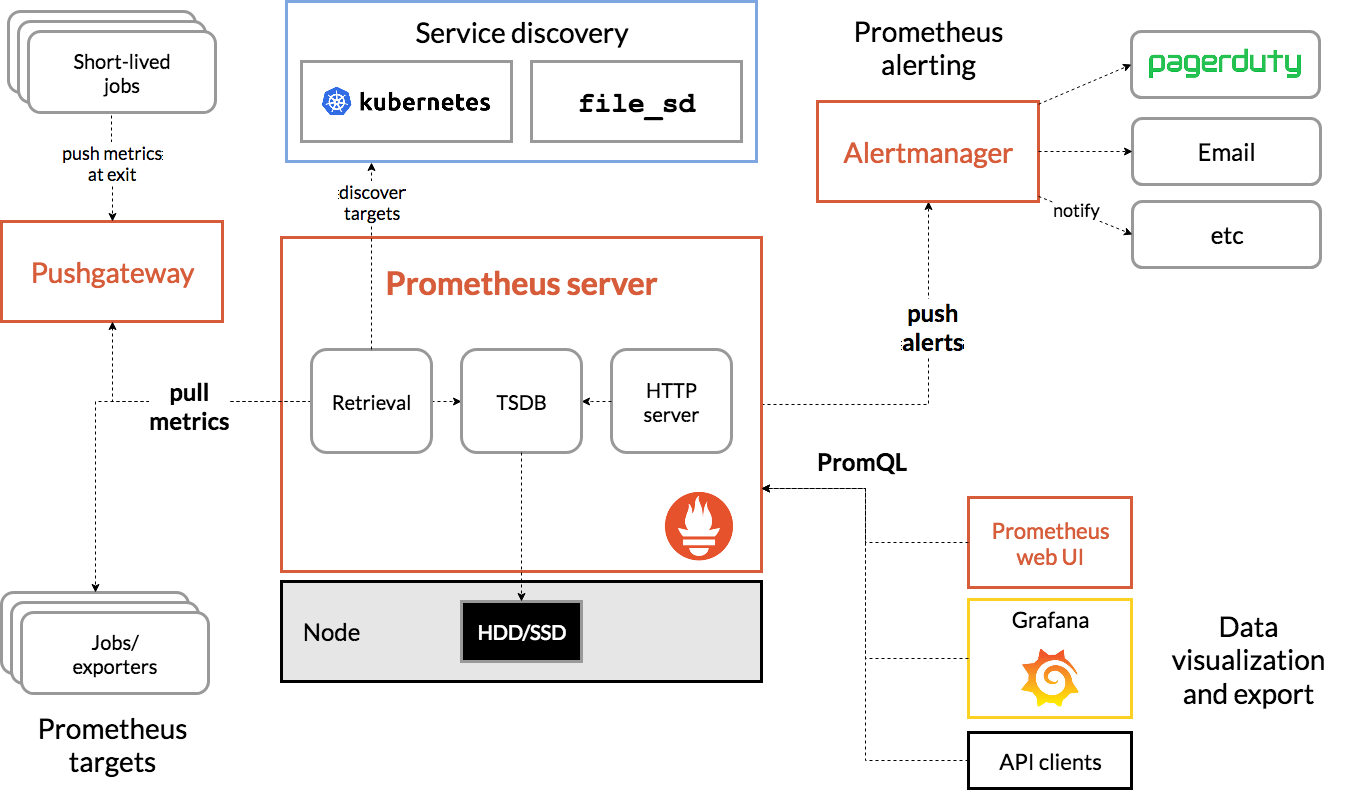
简单介绍一下
上图左边部份
最左边这块就是采集的,采集谁监控谁,一般是一些短周期的任务,比如cronjob这样的任务,也可以是一些持久性的任务,其实主要就是一些持久性的任务,比如web服务,也就是持续运行的,暴露一些指标,像短期任务呢,处理一下就关了,分为这两个类型,短期任务会用到Pushgateway,专门收集这些短期任务的。
上图中间部份
中间这块就是Prometheus它本身,内部是有一个TSDB的数据库的,从内部的采集和展示Prometheus它都可以完成,展示这块自己的这块UI比较lou,所以借助于这个开源的Grafana来展示,所有的被监控端暴露完指标之后,Prometheus会主动的抓取这些指标,存储到自己TSDB数据库里面,提供给Web UI,或者Grafana,或者API clients通过PromQL来调用这些数据,PromQL相当于Mysql的SQL,主要是查询这些数据的。
上图中间上半部份
中间上面这块是做服务发现的,也就是你有很多的被监控端时,手动的去写这些被监控端是不现实的,所以需要自动的去发现新加入的节点,或者以批量的节点,加入到这个监控中,像k8s它内置了k8s服务发现的机制,也就是它会连接k8s的API,去发现你部署的哪些应用,哪些pod,通通的都给你暴露出去,监控出来,也就是为什么K8S对prometheus特别友好的地方,也就是它内置了做这种相关的支持了。
上图右边上半部份
右上角是Prometheus的告警,它告警实现是有一个组件的,Alertmanager,这个组件是接收prometheus发来的告警就是触发了一些预值,会通知Alertmanager,而Alertmanager来处理告警相关的处理,然后发送给接收人,可以是email,也可以是企业微信,或者钉钉,也就是它整个的这个框架,分为这5块。
数据模型
Prometheus将所有数据存储为时间序列;具有相同度量名称以及标签属于同一个指标。
每个时间序列都由度量标准名称和一组键值对(也成为标签)唯一标识。 也就是查询时
也会依据这些标签来查询和过滤,就是写PromQL时
时间序列格式:
<metric name>{<label name>=<label value>, ...}指标的名字+花括号里面有很多的值
示例:
api_http_requests_total{method="POST", handler="/messages"}( 名称 )(里面包含的POST请求,GET请求,请求里面还包含了请求的资源,比如messages或者API)里面可以还有很多的指标,比如请求的协议,或者携带了其他HTTP头的字段,都可以进行标记出来,就是想监控的都可以通过这种方式监控出来。
作业和实例
实例:可以抓取的目标称为实例(Instances),用过zabbix的都知道被监控端是称为什么,一般就是称为主机,被监控端,而在prometheus称为一个实例。
作业:具有相同目标的实例集合称为作业(Job),也就是将你的被监控端作为你个集合,比如做一个分组,web 服务有几台,比如有3台,写一个job下,这个job下就是3台,就是做一个逻辑上的分组
监控指标
k8s监控
- Node资源利用率 :一般生产环境几十个node,几百个node去监控
- Node数量 :一般能监控到node,就能监控到它的数量了,因为它是一个实例,一个node能跑多少个项目,也是需要去评估的,整体资源率在一个什么样的状态,什么样的值,所以需要根据项目,跑的资源利用率,还有值做一个评估的,比如再跑一个项目,需要多少资源。
- Pods数量(Node):其实也是一样的,每个node上都跑多少pod,不过默认一个node上能跑110个pod,但大多数情况下不可能跑这么多,比如一个128G的内存,32核cpu,一个java的项目,一个分配2G,也就是能跑50-60个,一般机器,pod也就跑几十个,很少很少超过100个。
- 资源对象状态 :比如pod,service,deployment,job这些资源状态,做一个统计。
Pod监控
- Pod数量(项目):你的项目跑了多少个pod的数量,大概的利益率是多少,好评估一下这个项目跑了多少个资源占有多少资源,每个pod占了多少资源。
- 容器资源利用率 :每个容器消耗了多少资源,用了多少CPU,用了多少内存
- 应用程序:这个就是偏应用程序本身的指标了,这个一般在我们运维很难拿到的,所以在监控之前呢,需要开发去给你暴露出来,这里有很多客户端的集成,客户端库就是支持很多语言的,需要让开发做一些开发量将它集成进去,暴露这个应用程序的想知道的指标,然后纳入监控,如果开发部配合,基本运维很难做到这一块,除非自己写一个客户端程序,通过shell/python能不能从外部获取内部的工作情况,如果这个程序提供API的话,这个很容易做到。
| 监控指标 | 实现 | 备注 |
|---|---|---|
| pod性能 | cAdvisor | 容器CPU,内存使用率 |
| node性能 | node-exporter | 节点CPU,内存使用率 |
| K8S资源对象 | kube-state-metrics | pod,deployment,service |
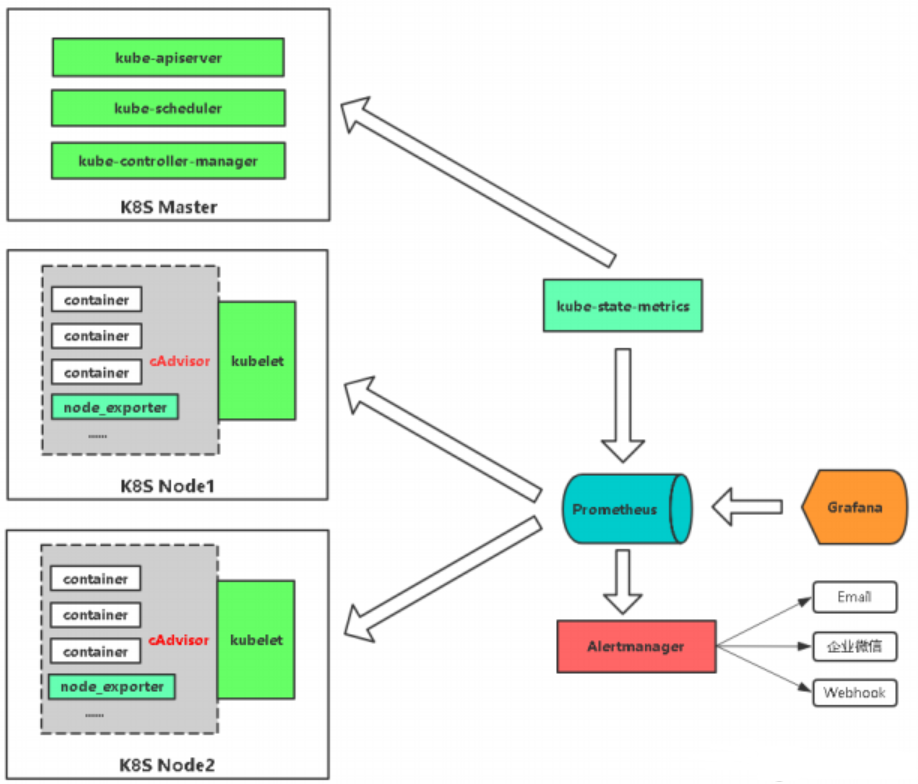
如果想监控node的资源,就可以放一个node_exporter,这是监控node资源的,node_exporter是Linux上的采集器,你放上去你就能采集到当前节点的CPU、内存、网络IO,等待都可以采集的。
如果想监控容器,k8s内部提供cAdvisor采集器,pod呀,容器都可以采集到这些指标,都是内置的,不需要单独部署,只知道怎么去访问这个Cadvisor就可以了。
如果想监控k8s资源对象,会部署一个kube-state-metrics这个服务,它会定时的API中获取到这些指标,帮你存取到Prometheus里,要是告警的话,通过Alertmanager发送给一些接收方,通过Grafana可视化展示。



 Asynq任务框架
Asynq任务框架 MCP智能体开发实战
MCP智能体开发实战 WEB架构
WEB架构 安全监控体系
安全监控体系